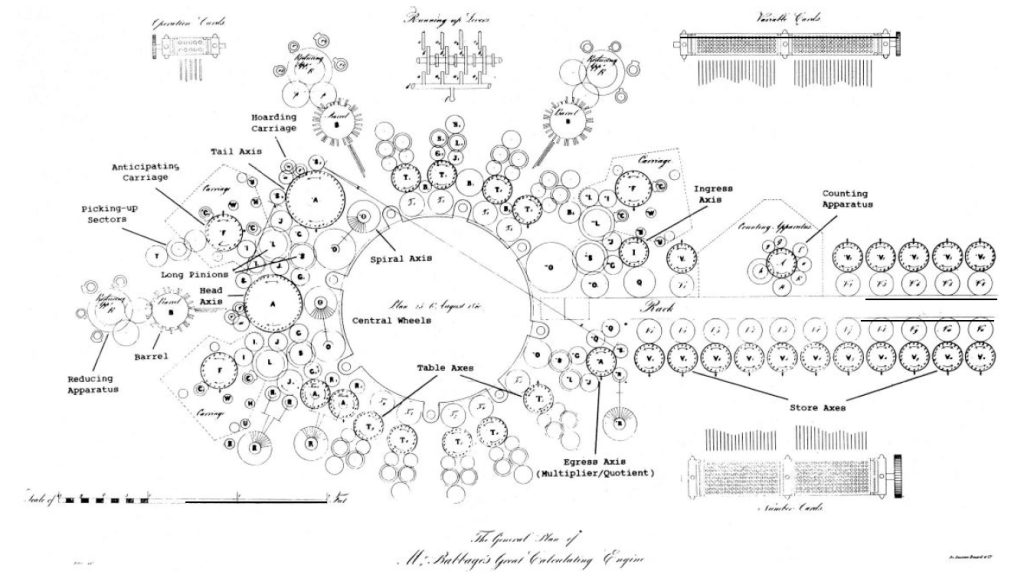
Something strange almost happened in 1840’s England just a few years into Queen Victoria’s long reign—a giant machine the size of a large shed, built of thousands of interlocking steel gears, driven by steam power, almost came to life—a thinking, mechanical automaton, the very image of Cyber Steampunk.
Cyber Steampunk is a genre of media that imagines an alternate history of a Victorian Age with advanced technology—airships and rockets and robots and especially computers—driven by steam power. Some of the classics that helped launch the genre are the animé movies Castle in the Sky (1986) by Hayao Miyazaki and Steam Boy (2004) by Katsuhiro Otomo and the novel The Difference Engine (1990) by William Gibson and Bruce Sterling. The novel pursues Ada Byron, Lady Lovelace, through the shadows of London by those who suspect she has devised a programmable machine that can win at gambling using steam and punched cards. This is not too far off from what might have happened in real life if Ada Lovelace had a bit more sway over one of her unsuitable suitors—Charles Babbage.
But Babbage, part genius, part fool, could not understand what Lovelace understood—for if he had, a Victorian computer built of oiled gears and leaky steam pipes, instead of tiny transistors and metallic leads, might have come a hundred years early as another marvel of the already marvelous Industrial Revolution. How might our world today be different if Babbage had seen what Lovelace saw?

Boundless Babbage
There is no question of Babbage’s genius. He was so far ahead of his time that he appeared to most people in his day to be a crackpot, and he was often treated as one. His father thought he was useless, and he told him so, because to be a scientist in the early 1800’s was to be unemployable, and Babbage was unemployed for years after college. Science was, literally, natural philosophy, and no one hired a philosopher unless they were faculty at some college. But Babbage’s friends from Trinity College, Cambridge, like William Whewell (future dean of Trinity) and John Herschel (son of the famous astronomer), new his worth and were loyal throughout their lives and throughout his trials.

Charles Babbage was a favorite at Georgian dinner parties because he was so entertaining to watch and to listen to. From personal letters of his friends (and enemies) of the time one gets a picture of a character not too different from Sheldon Cooper on the TV series The Big Bang Theory—convinced of his own genius and equally convinced of the lack of genius of everyone else and ready to tell them so. His mind was so analytic, that he talked like a walking computer—although nothing like a computer existed in those days—everything was logic and functions and propositions—hence his entertainment value. No one understood him, and no one cared—until he ran into a young woman who actually did, but more of that later.
One summer day in 1821, Babbage and Herschel were working on mathematical tables for the Astrophysical Society, a dull but important job to ensure that star charts and moon positions could be used accurately for astronomical calculations and navigation. The numbers filled column after column, page after page. But as they checked the values, the two were shocked by how many entries in the tables were wrong. In that day, every numerical value of every table or chart was calculated by a person (literally called a computer), and people make mistakes. Even as they went to correct the numbers, new mistakes would crop in. In frustration, Babbage exclaimed to Herschel that what they needed was a steam-powered machine that would calculate the numbers automatically. No sooner had he said it, than Babbage had a vision of a mechanical machine, driven by a small steam engine, full of gears and rods, that would print out the tables automatically without flaws.
Being unemployed (and unemployable) Babbage had enough time on his hands to actually start work on his engine. He called it the Difference Engine because it worked on the Method of Differences—mathematical formulas were put into a form where a number was expressed as a series, and the differences between each number in the series would be calculated by the engine. He approached the British government for funding, and it obliged with considerable funds. In the days before grant proposals and government funding, Babbage had managed to jump start his project and, in a sense, gain employment. His father was not impressed, but he did not live long enough to see what his son Charles could build. Charles inherited a large sum from his father (the equivalent of about 14 million dollars today), which further freed him to work on his Difference Engine. By 1832, he had finally completed a seventh part of the Engine and displayed it in his house for friends and visitors to see.
This working section of the Difference Engine can be seen today in the London Science Museum. It is a marvel of steel and brass, consisting of three columns of stacked gears whose enmeshed teeth represent digital numbers. As a crank handle is turned, the teath work upon each other, generating new numbers through the permutations of rotated gear teeth. Carrying tens was initially a problem for Babbage, as it is for school children today, but he designed an ingenious mechanical system to accomplish the carry.

All was going well, and the government was pleased with progress, until Charles had a better idea that threatened to scrap all he had achieved. It is not known how this new idea came into being, but it is known that it happened shortly after he met the amazing young woman: Ada Byron.
Lovely Lovelace
Ada Lovelace, born Ada Byron, had the awkward distinction of being the only legitimate child of Lord Byron, lyric genius and poet. Such was Lord Byron’s hedonist lifestyle that no-one can say for sure how many siblings Ada had, not even Lord Byron himself, which was even more awkward when his half-sister bore a bastard child that may have been his.

Ada’s high-born mother prudently divorced the wayward poet and was not about to have Ada pulled into her father’s morass. Where Lord Byron was bewitched (some would say possessed) by art and spirit, the mother sought an antidote, and she encouraged Ada to study hard cold mathematics. She could not have known that Ada too had a genius like her father’s, only aimed differently, bewitched by the beauty in the sublime symbols of math.
An insight into the precocious child’s way of thinking can be gained from a letter that the 12-year-old girl wrote to her mother who was off looking for miracle cures for imaginary ills. At that time in 1828, in a confluence of historical timelines in the history of mathematics, Ada and her mother (and Ada’s cat Puff) were living at Bifrons House which was the former estate of Brook Taylor, who had developed the Taylor’s series a hundred years earlier in 1715. In Ada’s letter, she describes a dream she had of a flying machine, which is not so remarkable, but then she outlined her plan to her mother to actually make one, which is remarkable. As you read her letter, you see she is already thinking about weights and material strengths and energy efficiencies, thinking like an engineer and designer—at the age of only 12 years!
In later years, Lovelace would become the Enchantress of Number to a number of her mathematical friends, one of whom was the strange man she met at a dinner party in the summer of 1833 when she was 17 years old. The strange man was Charles Babbage, and when he talked to her about his Difference Engine, expecting to be tolerated as an entertaining side show, she asked pertinent questions, one after another, and the two became locked in conversation.
Babbage was a recent widower, having lost his wife with whom he had been happily compatible, and one can only imagine how he felt when the attractive and intelligent woman gave him her attention. But Ada’s mother would never see Charles as a suitable husband for her daughter—she had ambitious plans for her, and she tolerated Babbage only as much as she did because of the affection that Ada had for him. Nonetheless, Ada and Charles became very close as friends and met frequently and wrote long letters to each other, discussing problems and progress on the Difference Engine.
In December of 1834, Charles invited Lady Byron and Ada to his home where he described with great enthusiasm a vision he had of an even greater machine. He called it his Analytical Engine, and it would surpass his Difference Engine in a crucial way: where the Difference Engine needed to be reconfigured by hand before every new calculation, the Analytical Engine would never need to be touched, it just needed to be programmed with punched cards. Charles was in top form as he wove his narrative, and even Lady Byron was caught up in his enthusiasm. The effect on Ada, however, was nothing less than a religious conversion.
Ada’s Notes
To meet Babbage as an equal, Lovelace began to study mathematics with an obsession, or one might say, with delusions of grandeur. She wrote “I believe myself to possess a most singular combination of qualities exactly fitted to make me pre-eminently a discoverer of the hidden realities of nature,” and she was convinced that she was destined to do great things.
Then, in 1835, Ada was married off to a rich but dull aristocrat who was elevated by royal decree to the Earldom of Lovelace, making her the Countess of Lovelace. The marriage had little effect on Charles’ and Ada’s relationship, and he was invited frequently to the new home where they continued their discussions about the Analytical Engine.
By this time Charles had informed the British government that he was putting all his effort into the design his new machine—news that was not received favorably since he had never delivered even a working Difference Engine. Just when he hoped to start work on his Analytical Engine, the government ministers pulled their money. This began a decade’s long ordeal for Babbage as he continued to try to get monetary support as well as professional recognition from his peers for his ideas. Neither attempt was successful at home in Britain, but he did receive interest abroad, especially from a future prime minister of Italy, Luigi Menabrae, who invited Babbage to give a lecture in Turin on his Analytical Engine. Menabrae later had the lecture notes published in French. When Charles Wheatstone, a friend of Babbage, learned of Menabrae’s publication, he suggested to Lovelace that she translate it into English. Menabrae’s publication was the only existing exposition of the Analytical Engine, because Babbage had never written on the Engine himself, and Wheatstone was well aware of Lovelace’s talents, expecting her to be one of the only people in England who had the ability and the connections to Babbage to accomplish the task.
Ada Lovelace dove into the translation of Menabrae’s “Sketch of the Analytical Engine Invented by Charles Babbage” with the single-mindedness that she was known for. Along with the translation, she expanded on the work with Notes of her own that she added, lettered from A to G. By the time she wrote them, Lovelace had become a top-rate mathematician, possibly surpassing even Babbage, and her Notes were three times longer than the translation itself, providing specific technical details and mathematical examples that Babbage and Menabrae only allude to.
On a different level, the character of Ada’s Notes stands in stark contrast to Charles’ exposition as captured by Menabrae: where Menabrae provided only technical details of Babbage’s Engine, Lovelace’s Notes captured the Engine’s potential. She was still a poet by disposition—that inheritance from her father was never lost.
Lovelace wrote:
We may say most aptly, that the Analytical Engine weaves algebraic patterns just as the Jacquard-loom weaves flowers and leaves.
Here she is referring to the punched cards that the Jacquard loom used to program the weaving of intricate patterns into cloth. Babbage had explicitly borrowed this function from Jacquard, adapting it to provide the programmed input to his Analytical Engine.
But it was not all poetics. She also saw the abstract capabilities of the Engine, writing
In studying the action of the Analytical Engine, we find that the peculiar and independent nature of the considerations which in all mathematical analysis belong to operations, as distinguished from the objects operated upon and from the results of the operations performed upon those objects, is very strikingly defined and separated.
Again, it might act upon other things besides number, where objects found whose mutual fundamental relations could be expressed by those of the abstract science of operations, and which should be also susceptible of adaptations to the action of the operating notation and mechanism of the engine.
Supposing, for instance, that the fundamental relations of pitched sounds in the science of harmony and of musical composition were susceptible of such expression and adaptations, the engine might compose elaborate and scientific pieces of music of any degree of complexity or extent.
Here she anticipates computers generating musical scores.
Most striking is Note G. This is where she explicitly describes how the Engine would be used to compute numerical values as solutions to complicated problems. She chose, as her own example, the calculation of Bernoulli numbers which require extensive numerical calculations that were exceptionally challenging even for the best human computers of the day. In Note G, Lovelace writes down the step-by-step process by which the Engine would be programmed by the Jacquard cards to carry out the calculations. In the history of computer science, this stands as the first computer program.
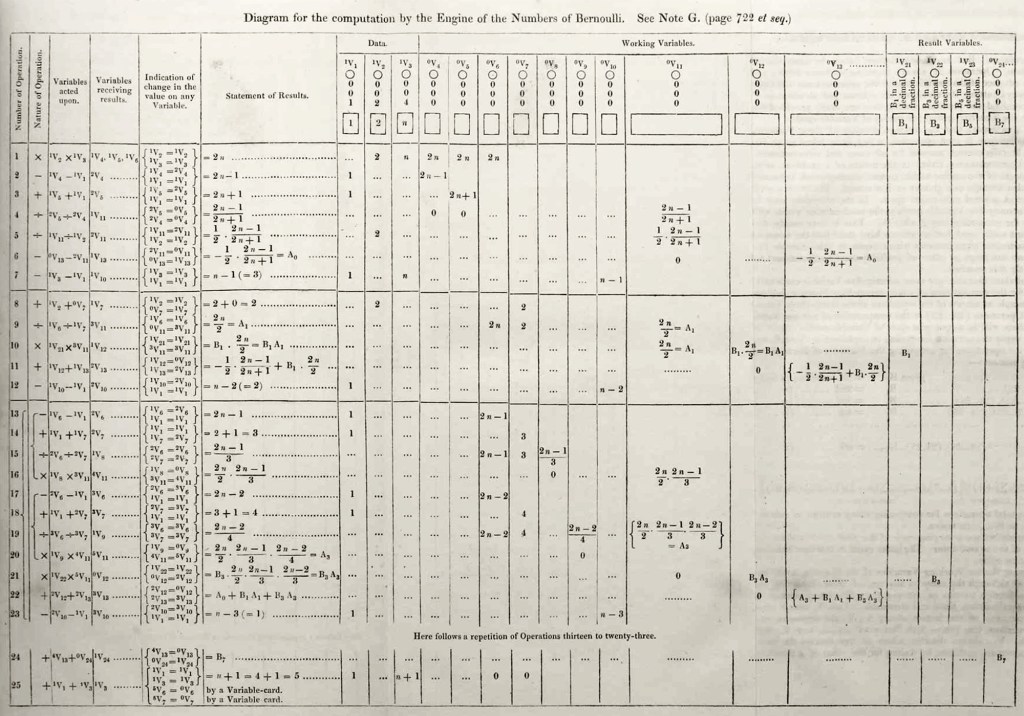
When it was time to publish, Babbage read over Lovelace’s notes, checking for accuracy, but he appears to have been uninterested in her speculations, possibly simply glossing over them. He saw his engine as a calculating machine for practical applications. She saw it for what we know today to be the exceptional adaptability of computers to all realms of human study and activity. He did not see what she saw. He was consumed by his Engine to the same degree as she, but where she yearned for the extraordinary, he sought funding for the mundane costs of machining and materials.
Ada’s Business Plan Pitch
Ada Lovelace watched in exasperation as Babbage floundered about with ill-considered proposals to the government while making no real progress towards a working Analytical Engine. Because of her vision into the potential of the Engine, a vision that struck her to her core, and seeing a prime opportunity to satisfy her own yearning to make an indelible mark on the world, she despaired in ever seeing it brought to fruition. Charles, despite his genius, was too impractical, wasting too much time on dead ends and incapable of performing the deft political dances needed to attract support. She, on the other hand, saw the project clearly and had the time and money and the talent, both mathematically and through her social skills, to help.
On Monday August 14, 1843, Ada wrote what might be the most heart-felt and impassioned business proposition in the history of computing. She laid out in clear terms to Charles how she could advance the Analytical Engine to completion if only he would surrender to her the day-to-day authority to make it happen. She was, in essence, proposing to be the Chief Operating Officer in a disruptive business endeavor that would revolutionize thinking machines a hundred years before their time. She wrote (she liked to underline a lot):
“Firstly: I want to know whether if I continue to work on & about your own great subject, you will undertake to abide wholly by the judgment of myself (or of any persons whom you may now please to name as referees, whenever we may differ), on all practical matters relating to whatever can involve relations with any fellow-creature or fellow-creatures.
Secondly: can you undertake to give your mind wholly & undividedly, as a primary object that no engagement is to interfere with, to the consideration of all those matters in which I shall at times require your intellectual assistance & supervision; & can you promise not to slur & hurry things over; or to mislay, & allow confusion and mistakes to enter into documents, &c?
Thirdly: if I am able to lay before you in the course of a year or two, explicit & honorable propositions for executing your engine, (such as are approved by persons whom you may now name to be referred to for their approbation), would there be any chance of your allowing myself & such parties to conduct the business for you; your own undivided energies being devoted to the execution of the work; & all other matters being arranged for you on terms which your own friends should approve?“
This is a remarkable letter from a self-possessed 28-year-old woman, laying out in explicit terms how she proposed to take on the direction of the project, shielding Babbage from the problems of relating to other people or “fellow-creatures” (which was his particular weakness), giving him time to focus his undivided attention on the technical details (which was his particular strength), while she would be the outward face of the project that would attract the appropriate funding.
In her preface to her letter, Ada adroitly acknowledges that she had been a romantic disappointment to Charles, but she pleads with him not to let their personal history cloud his response to her proposal. She also points out that her keen intellect would be an asset to the project and asks that he not dismiss it because of her sex (which a biased Victorian male would likely do). Despite her entreaties, this is exactly what Babbage did. Pencilled on the top of the original version of Ada’s letter in the Babbage archives is his simple note: “Tuesday 15 saw AAL this morning and refused all the conditions”. He had not even given her proposal 24 hours consideration as he indeed slurred and hurried things over.
Aftermath
Babbage never constructed his Analytical Engine and never even wrote anything about it. All his efforts would have been lost to history if Alan Turing had not picked up on Ada’s Notes and expanded upon them a hundred years later, bringing both her and him to the attention of the nascent computing community.
Ada Lovelace died young in 1852, at the age of 36, of cancer. By then she had moved on from Babbage and was working on other things. But she never was able to realize her ambition of uncovering such secrets of nature as to change the world.
Ada had felt from an early age that she was destined for greatness. She never achieved it in her lifetime and one can only wonder what she thought about this as she faced her death. Did she achieve it in posterity? This is a hotly debated question. Some say she wrote the first computer program, which may be true, but little programming a hundred years later derived directly from her work. She did not affect the trajectory of computing history. Discovering her work after the fact is interesting, but cannot be given causal weight in the history of science. The Vikings were the first Europeans to discover America, but no-one knew about it. They did not affect subsequent history the way that Columbus did.
On the other hand, Ada has achieved greatness in a different way. Now that her story is known, she stands as an exemplar of what scientific and technical opportunities look like, and the risk of ignoring them. Babbage also did not achieve greatness during his lifetime, but he could have—if he had not dismissed her and her intellect. He went to his grave embittered rather than lauded because he passed up an opportunity he never recognized.
By David D. Nolte, June 26, 2023
References
[1] Facsimile of “Sketch of the Analytical Engine Invented by Charles Babbage” translated by Ada Lovelace from Harvard University.
[2] Facsimile of Ada Lovelace’s “Notes by the Translator“.
[3] Stephen Wolfram, “Untangling the Tale of Ada Lovelace“, Wolfram Writings (2015).
[4] J. Essinger, “Charles and Ada : The computer’s most passionate partnership,” (History Press, 2019).
[5] D. Swade, The Difference Engine: Charles Babbage and the quest to build the first computer (Penguin Books, 2002).
[6] W. Gibson, and B. Sterling, The Difference Engine (Bantam Books, 1992).
[7] L. J. Snyder, The Philosophical Breakfast Club : Four remarkable friends who transformed science and changed the world (Broadway Books, 2011).
[8] Allan G. Bromley, Charles Babbage’s Analytical Engine, 1838, Annals of the History of Computing, Volume 4, Number 3, July 1982, pp. 196 – 217