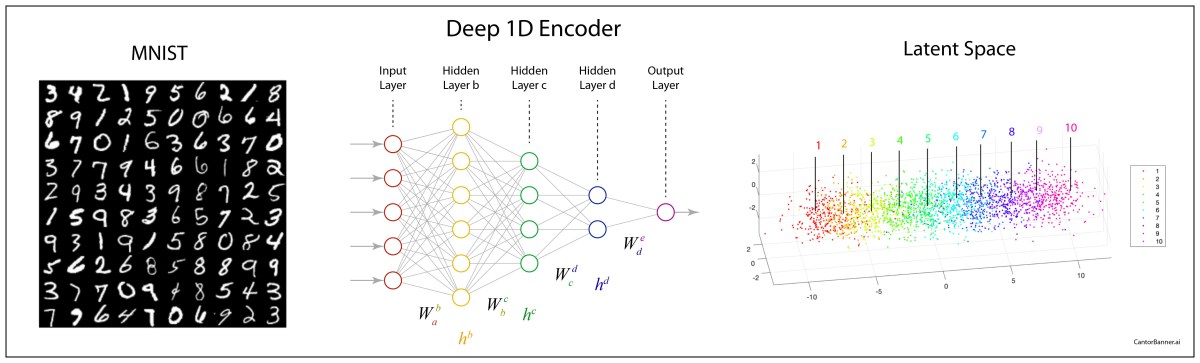
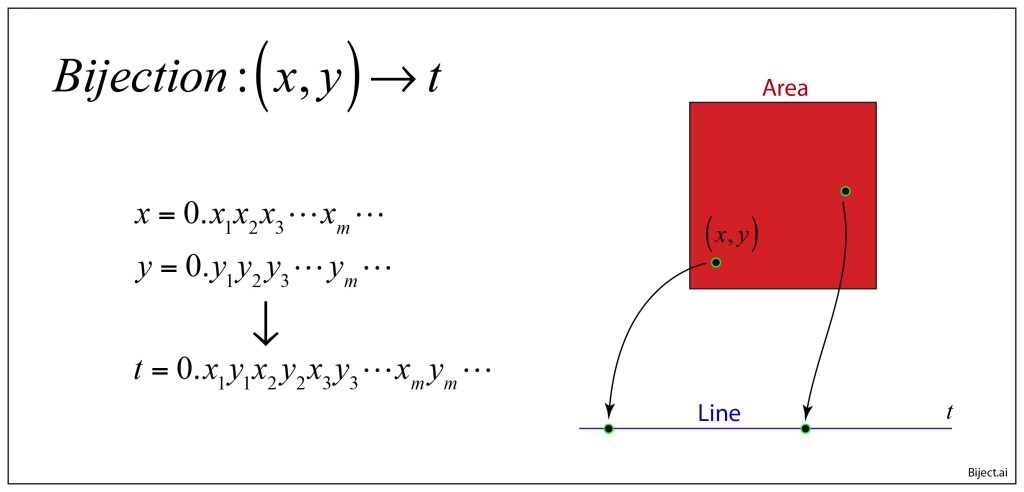
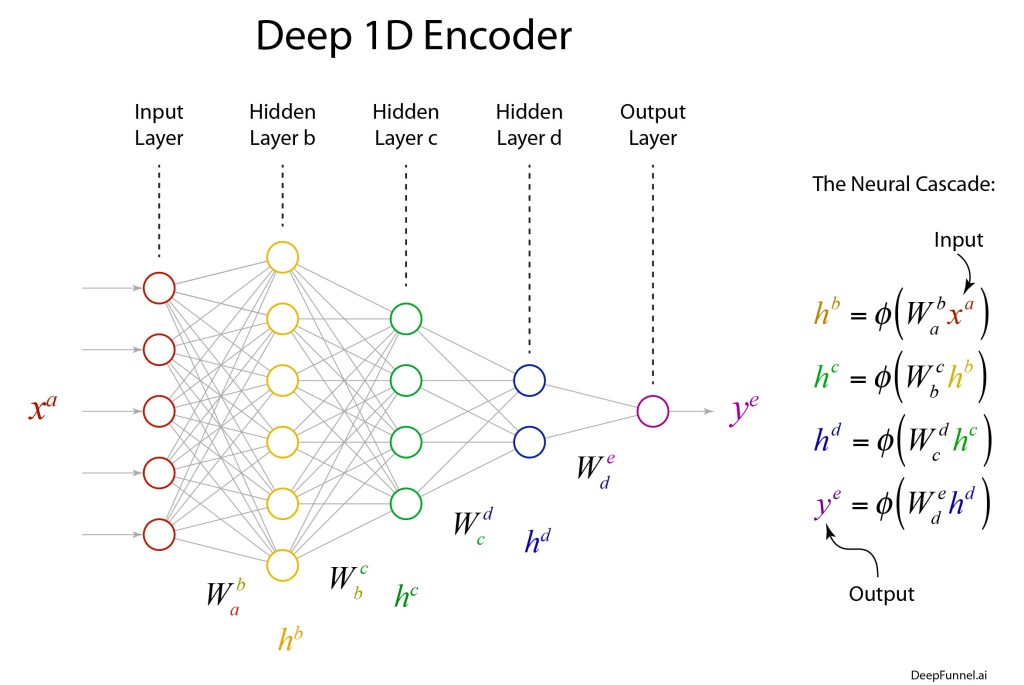
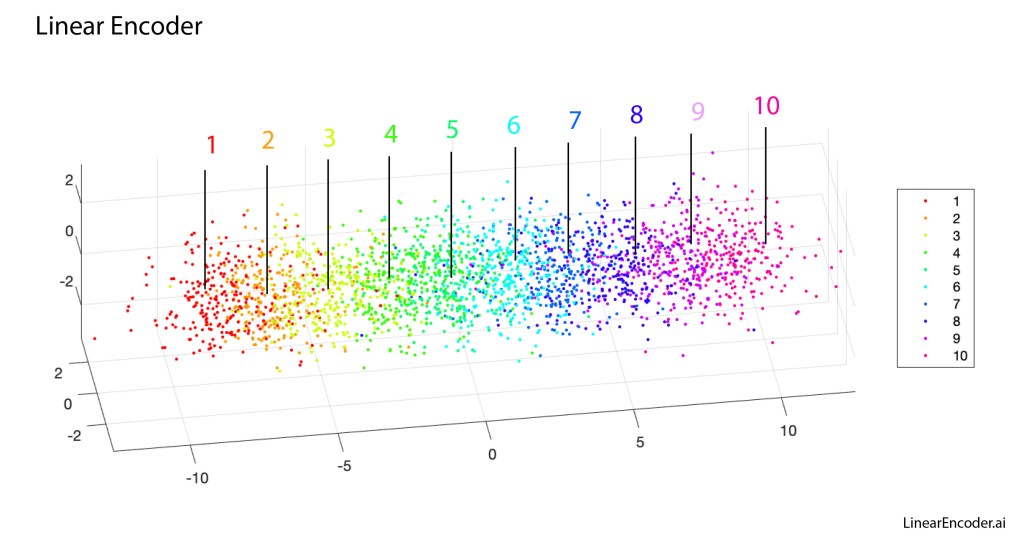
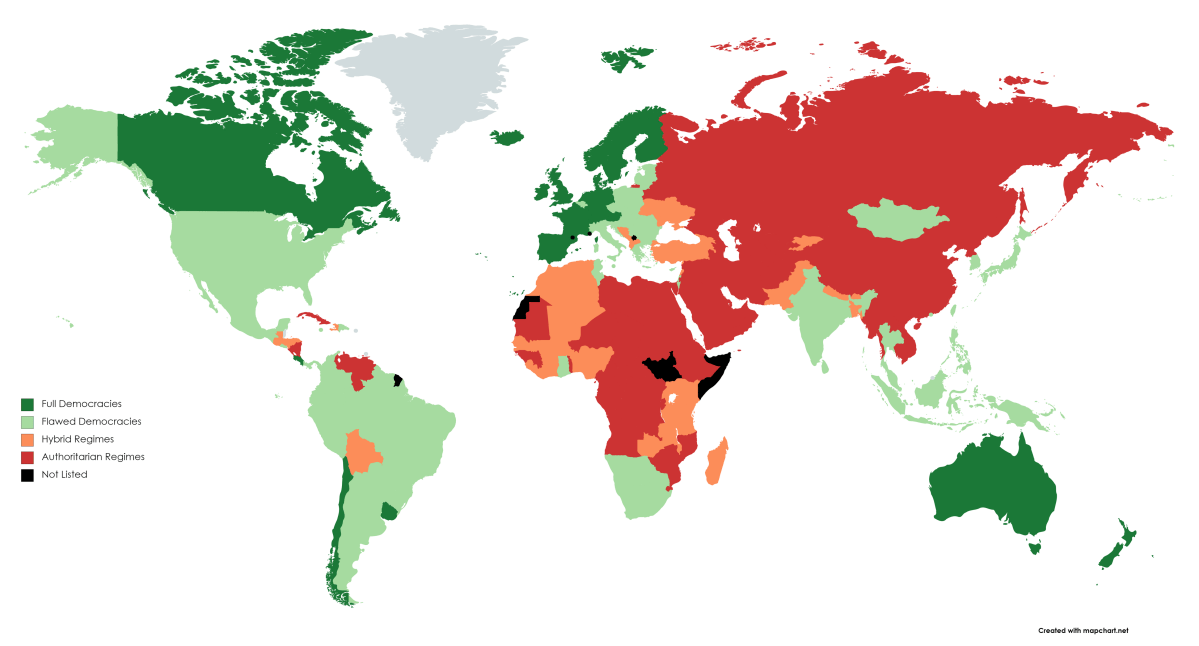
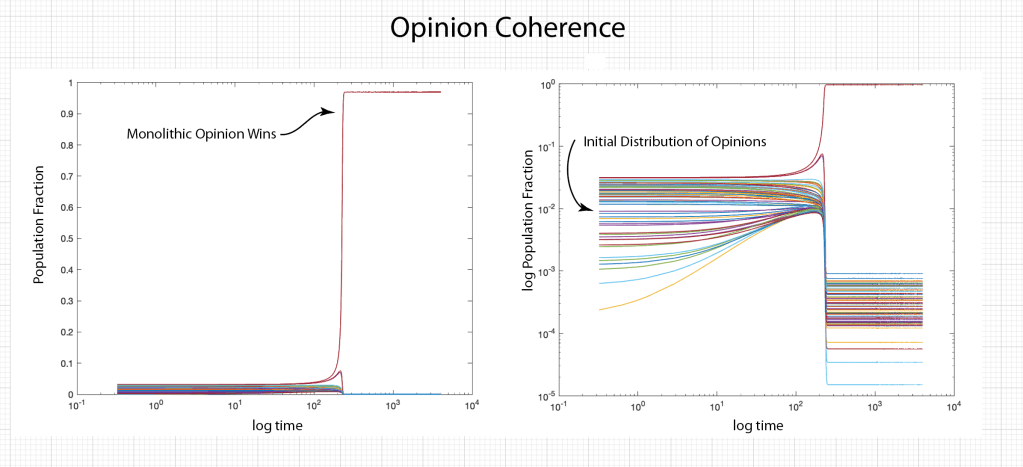
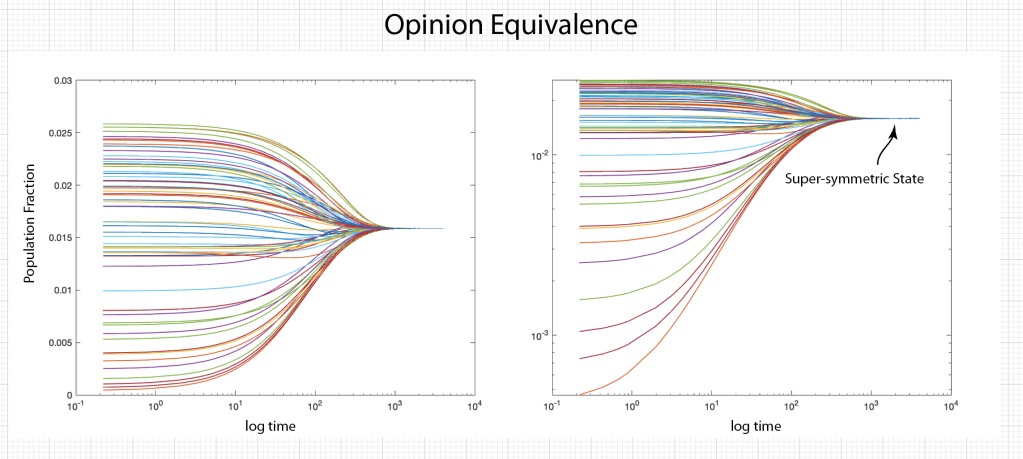
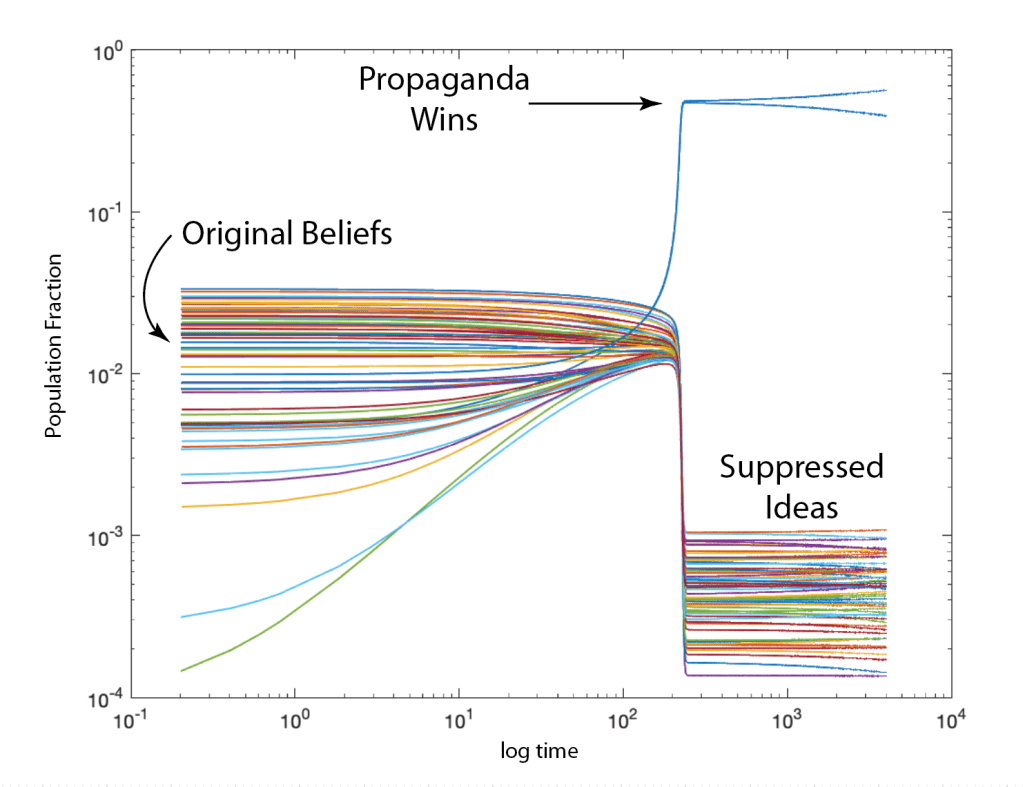
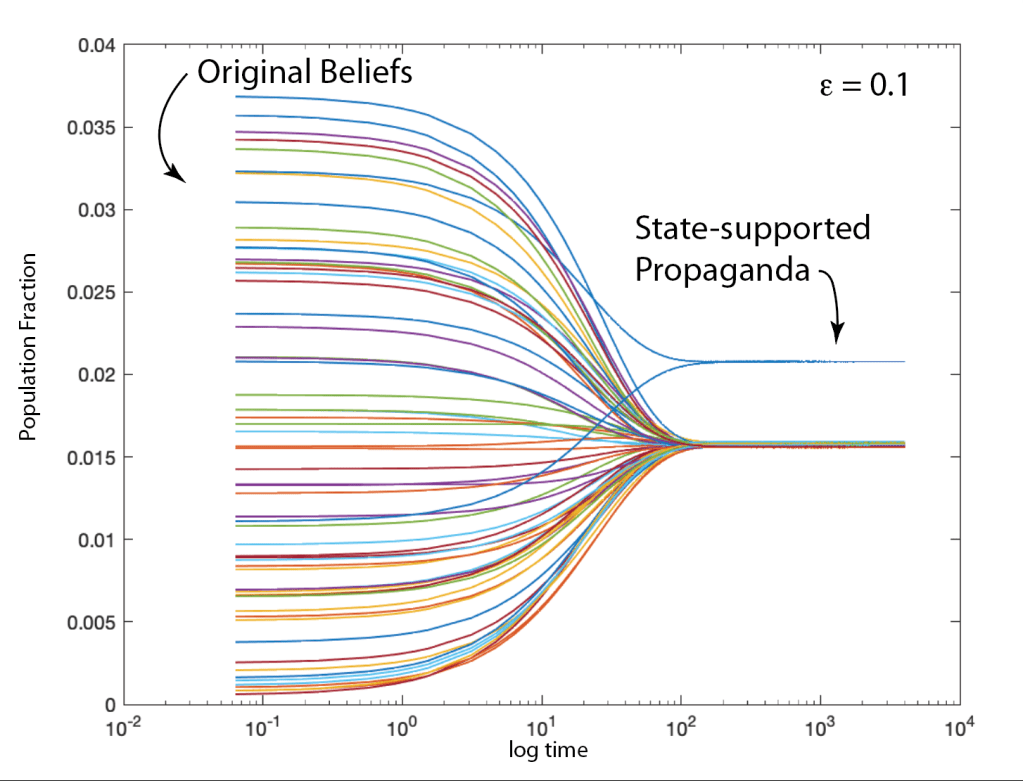
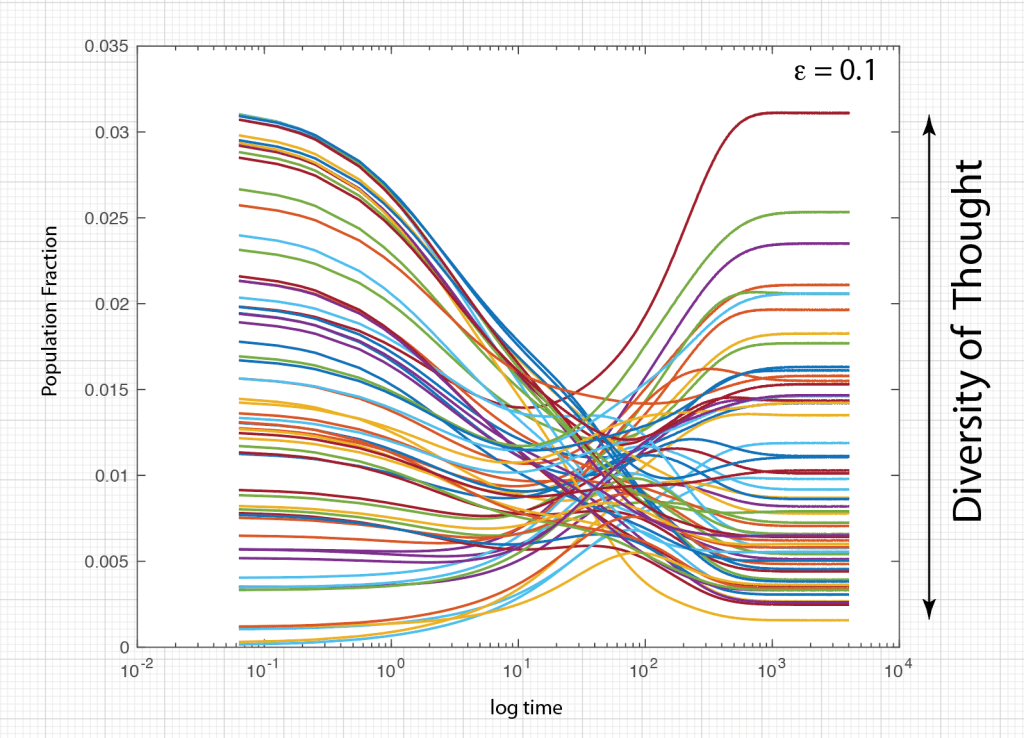
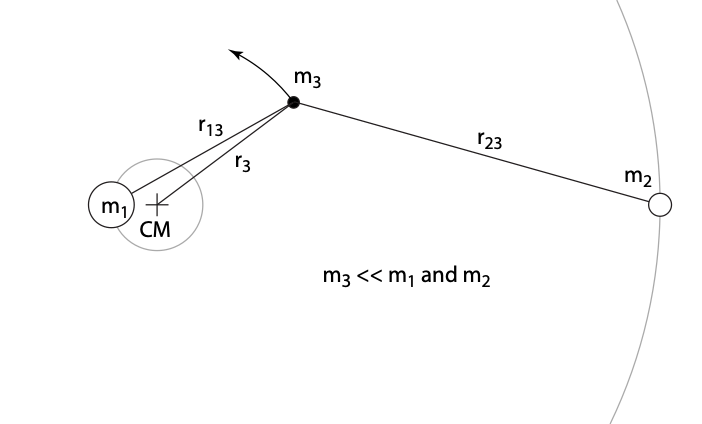
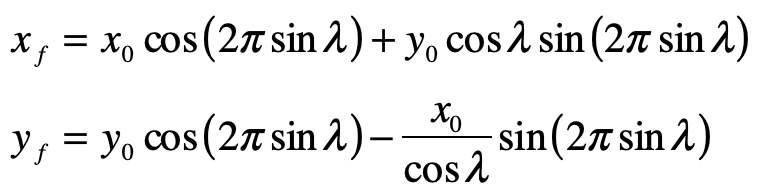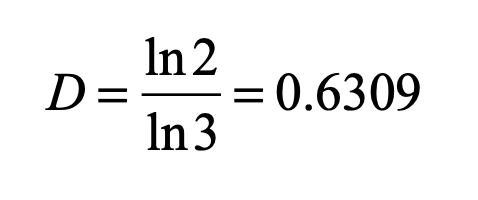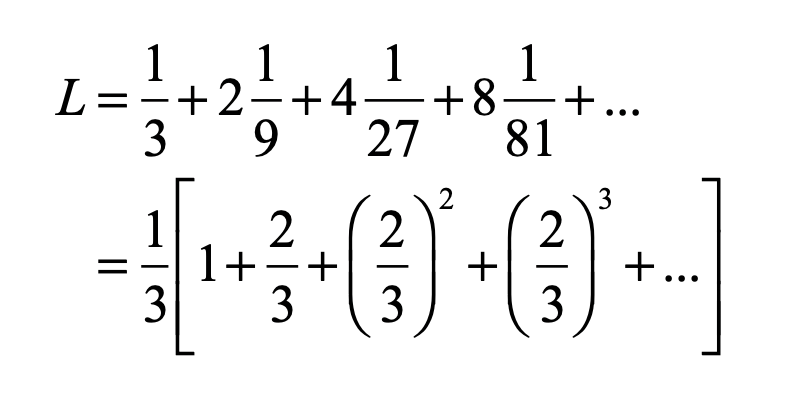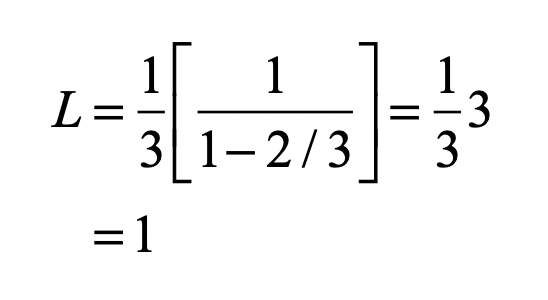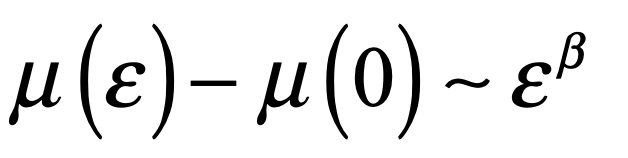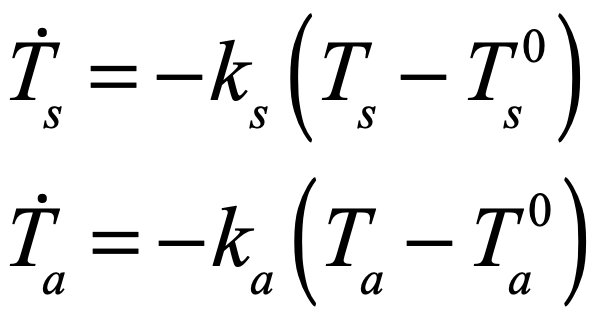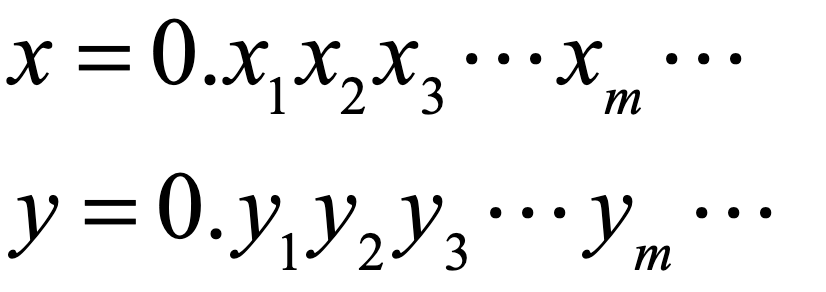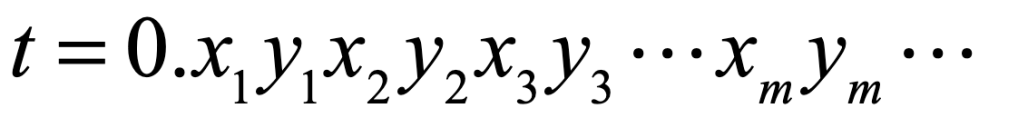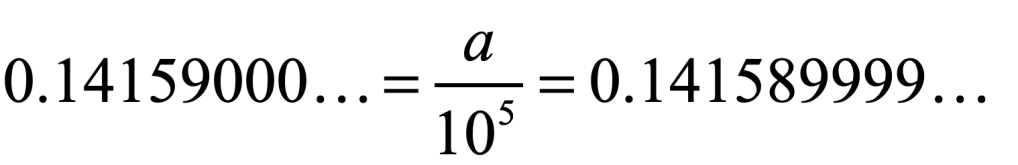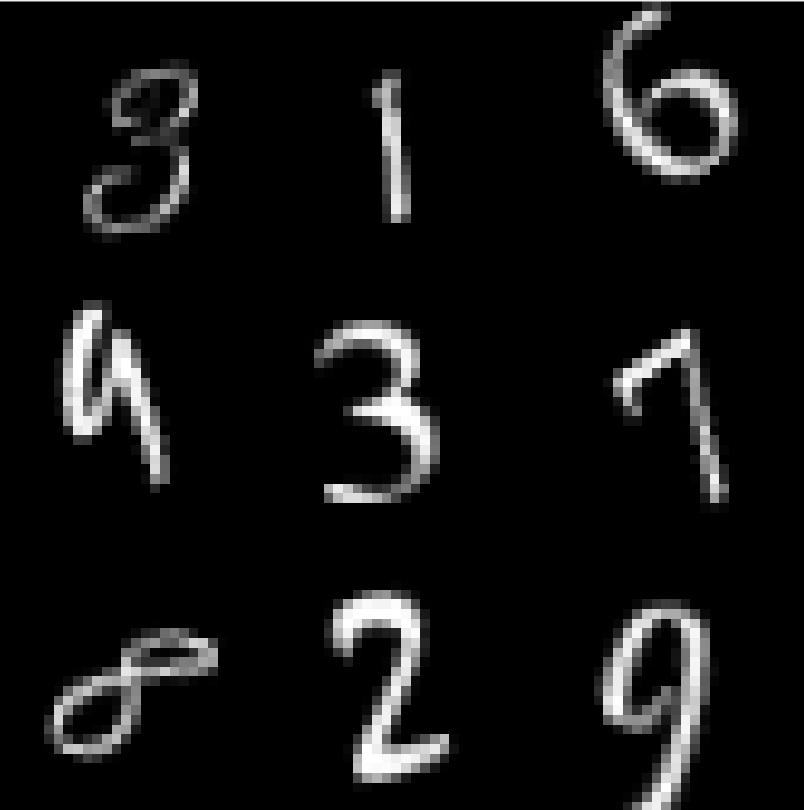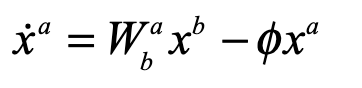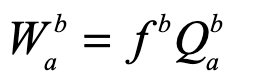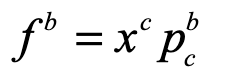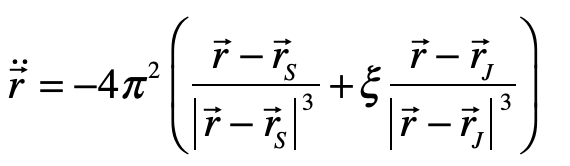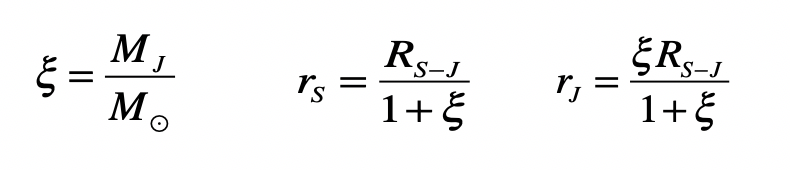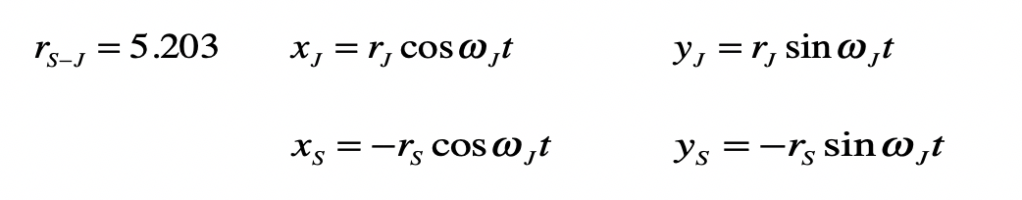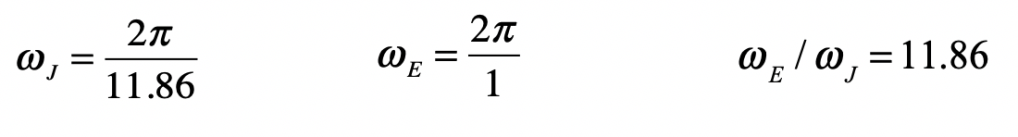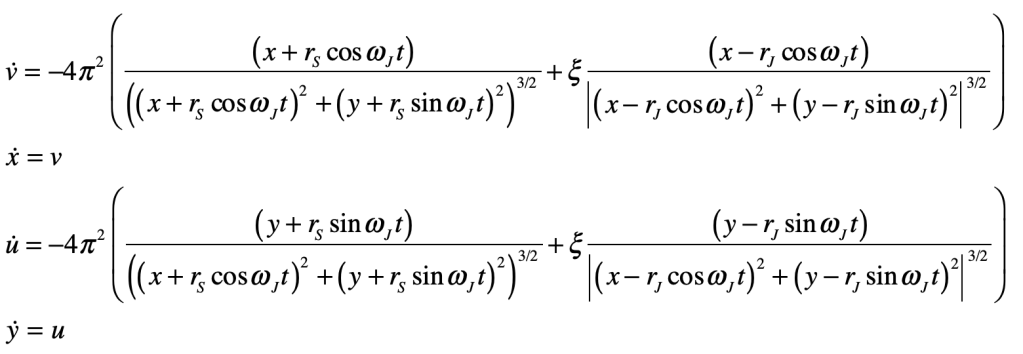Once upon a time the World was flat, and sailors feared falling off the edge if they sailed too far…at least that is how the fairy tale is told.
Flat World was a simple World. Its inhabitants, the Flatworlders, carried vectors abount with them, vectors that were thick bundles of arrows, bound in a sheaf, that tended to point in a fixed direction. In Flat World, once a vector had been oriented one way, it kept that orientation, no matter what path the Flatworlder took, always being exactly the same when it returned to its starting point.
Then came Cristobal Colon, and Carl Gauss and Bernhard Riemann, and Flat World became Round World, and the carrying around of vectors was no longer such a simple thing. The surprising part was, when vectors returned to their starting point, even if they were carried with the greatest of care never to turn them or twist them, carrying them always parallel to themselves, they were never the same. At the end of every different journey, they pointed in a different direction.
How can this be? How can a vector, that was transported always parallel to itself, end up pointing in a different direction when it was carried around a closed loop?
The answer is Holonomy!
Great Circle Routes
We were taught in Euclidean Geometry that the shortest path between two points is a straight line. This lesson was fine for Flat World. But now that we live in Round Riemann World, we know that the shortest distance between two points on the surface of the Earth is along a great circle route. All great circles are Earth circumferences. They are defined by three points: the starting point, the ending point and the center of the Earth. The three points define a plane that intersects the surface of the Earth along a great circle.
Fig. 1. Great circle route from Rio de Janeiro, Brazil, to Seoul, Korea on a Winkel Tripel projection of the Earth.
The practical demonstration that great circles are shortest paths can be done with a string and a globe. Pick any two points on the surface of the globe and stretch the string tightly between them so that the string lies taught on the surface of the globe. If the two points are far enough apart (but no so far that they are nearly antipodal), then the string takes on the arc of a circle centered on the center of the globe.
Shortest paths on a curved surface, like a globe, are also known as geodesics. And now that we have our geodesic paths for the Earth, we can start playing around with the parallel transportation of vectors.
Parallel Transport
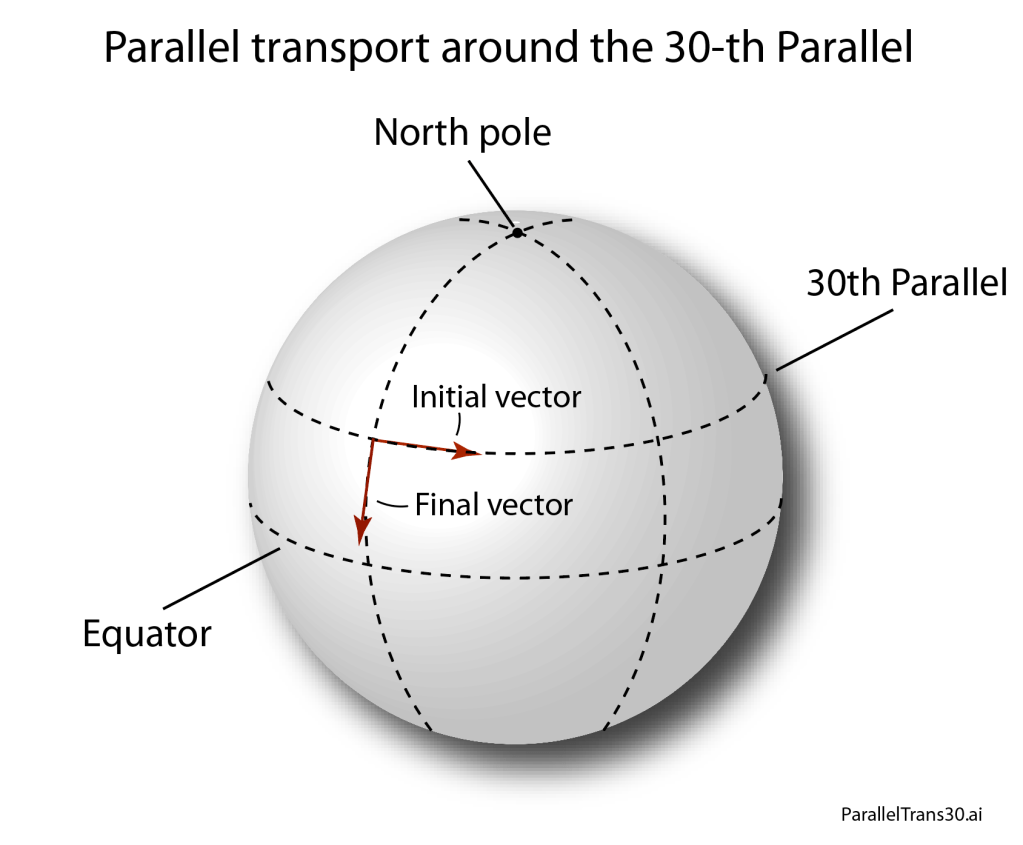
The game is simple. Start at the Equator with a vector that is pointing due North. Now, move the vector due North along a line of longitude (a geodesic) until you hit the North Pole. All the while, as you carry it along, the vector continues pointing due North on the surface of the Earth, never deviating. When you reach the North Pole, take a sharp turn right by 90 degrees, being careful not to twist or turn the vector in any way. Now, carry the vector with you due South along a new line of longitude until you hit the Equator, where again you take a sharp right turn by 90 degrees, and once again careful not to twist or turn the vector in any way. Then return to your starting point.
What you find, when you return home, is that the vector has turned through an angle of 90 degrees. Despite how careful you were never to twist or turn it—it has turned nonetheless. This is holonomy.
Fig. 2. Parallel transport around a geodesic triangle.Start at the equator with the vector pointing due North. Transport it without twisting it to the North Pole. Take a right turn, careful not to twist the vector, and proceed to the equator where you take another right turn and return to the starting point. Without ever twisting the vector, it has nonetheless rotated by 90-degrees over the closed path.
Holonomy
Holonomy, or more specifically Riemann holonomy, is the intrinsic twisting of vectors as they are transported parallel to themselves around a closed loop on a curved surface. The twist is something “outside” of the local transport of the vector. In the case of the Earth, this “outside” element is the curvature of the Earth’s surface. Locally, the Earth looks flat, and the vector is moved so that it always points in the same direction. But globally, the vector can slowly tilt as it moves along a geodesic path.
For the example of parallel transport on the Earth, look at the vector at its starting point and the vector when it reaches the North pole. Clearly the vector has rotated by 90 degrees, even despite of, or actually because of, its perfect Northward orientation along the line of longitude.
In this specific example, the solid angle of the closed path is a perfect eighth part of the total 4π solid angle of the surface, or 4π/8 = π/2. The angle by which the vector rotated on this path is precisely the same as the subtended solid angle. This is no coincidence—it is the consequence of the Gauss-Bonnet Theorem.
This theorem holds for any arbitrary closed path because any path can be viewed as if it were made up of lots of little segments of great circles. You can even pick a path that crosses itself, taking care to keep track of minus signs as solid angles add and subtract. For example, a perfect figure eight, if followed around smoothly, has no holonomy, because the two halves cancel.
Here, alas, we must leave our simple geometric games with great circles on the globe. To delve deeper into the origins of holonomy, it is time to turn to differential geometry.
Differential Geometry
Differential geometry is the application of differential calculus to geometry, in particular to geometric subspaces, also known as manifolds. A good example is the surface of a sphere embedded in three-dimensional space. The surface of a sphere has intrinsic curvature, where the curvature is defined as the inverse of the radius of the sphere.
One of the cornerstones of differential geometry is the operator known as the covariant derivative. It is defined as
This covariant derivative is a master at bookkeeping. Notice how the item on the left has an a-up and a b-down, as does the first term on the right. And if we think of the c-up and -down as canceling in the last term, then again we have a-up and b-down. The small-case “del” on the right is the usual partial derivative of Va with respect to xb. The second term on the right takes care of the intrinsic “twist” of the coordinates caused by curvature. As a bookkeeping device, covariant derivatives take care of the variation of a function as well as of the underlying variation of the coordinate frame. (The covariant derivative was crucial for Einstein when he was developing his General Theory of Relativity applied to gravity.)
One of the most important discoveries in differential geometry was may by Tullio Levi-Civita in 1917. Years before, Levi-Civita had helped develop tensor calculus with his advisor Gregorio Ricci-Curbastro at the University of Padua, and they published a seminal review paper in 1901 that Marcel Grossmann brought to Einstein’s attention when he was struggling to reconcile special relativity with gravity. Einstein and Levi-Civita corresponded in a series of famous letters in early 1915 as Einstein zeroed in on the final theory of General Relativity. Interestingly, that correspondence had as profound an effect on Levi-Civita as it had on Einstein. Once Einstein’s new theory was published in late 1915, Levi-Civita returned to tensor calculus to answer a critical question: What was the geometric meaning of the covariant derivative that was so crucial to the new theory of gravity?
To answer this question, Levi-Civita defined a new form of parallelism that held for vector fields on curved manifolds. The new definition stated that during the parallel transport of a vector along a path, its covariant derivative along that path vanishes. This definition is contained in the expression
where the ub on the left is the tangent vector of the path. Expanding this expression gives
and simplifying the first term yields the equation for parallel transport
For the surface of the sphere, with two variables θ and φ, these lead to two coupled ODEs
The Christoffel symbols for a spherical surface are
Yielding the equations for Parallel Transport of a vector on the Earth
These equations are all you need to calculate how much a vector rotates for any path taken across the face of the Earth.
Example: Parallel Transport Around a line of Latitude
One particularly simple path is a line of latitude. Lines of latitude are not geodesics (except for the Equator) and hence there will be a contribution to the twist of the vector caused by the curvature of the Earth. For lines of latitude, the equations of Parallel Transport become
The line element is
leading to the flow equations
where theta is fixed (in this case the angle relative to the North Pole) and φ is the dependent variable.
Fig. 3. A vector that originally points due East on the 30th Parallel is rotated by 90-degrees during parallel transport, ending by pointing due South.
These copled ODEs are recognized as simple oscillations with the flow
and the initial value problem has the solution
where the angular frequency is the geometric mean of the coefficients
where λ is the latitude.
For a full rotation around a closed line of latitude, the parallel-transported vector components are
As an example, take an initial vector [0, 1] pointing due East along the line of latitude. Then parallel-transport it around latitude 30o North. This gives the final vector the components
which is now pointing due South. The vector has been rotated by 90-degrees even though it was transported always parallel to itself on the surface of the Earth. The solid angle subtended by the 30-th parallel is exactly π/2.
One final bookkeeping step is needed. It looks like the magnitude of the vector changed during the transport: y0 = 1, but xf = cosλ. However, cosλ = sinθ, which is exactly the metric coefficient on the dφ term of the line element, and the vector retains its magnitude in spherical coordinates.
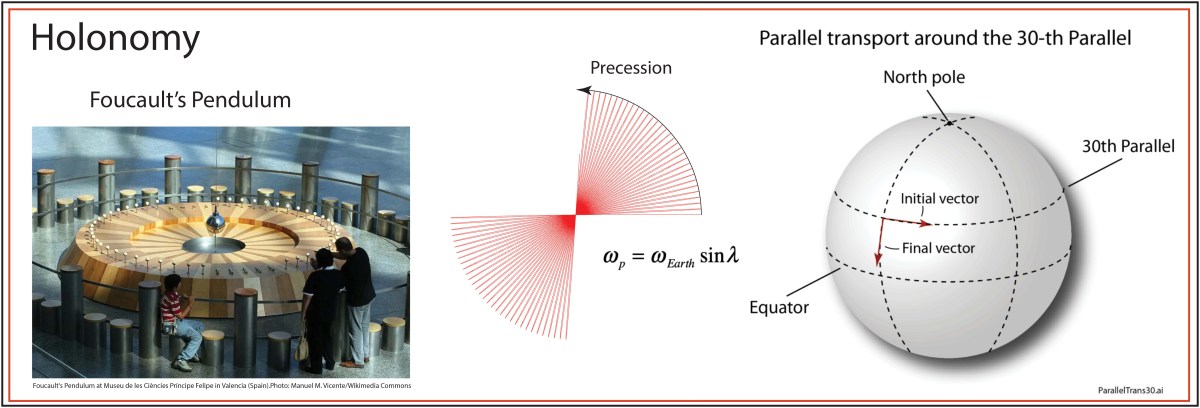
Foucault’s Pendulum
Holonomy is a subtle effect, and it’s hard to find good examples in real life where it matters. But there is one demonstration that almost anyone has seen, at least anyone with an interest in science: Foucault’s pendulum. This is the very long pendulum that is often found in science museums around the world. As the Earth turns, the plane of oscillation of the pendulum slowly turns, and the pendulum bob often knocks down blocks that the museum staff set up in the morning to track the precessing plane.
In a classical mechanics class, the precession of Foucault’s pendulum is usually derived through the effect of the Coriolis force on the moving pendulum bob. The answer for the precession frequency, after difficult integrations between non-inertial frames, is
Alternatively, the normal vector to the plane of oscillation can be viewed as parallel-transported around a closed loop at constant latitude. The amount of precession per day is
which is exactly the same thing. Therefore, Foucault’s pendulum is a striking and exact physical demonstration of Whole World Holonomy.
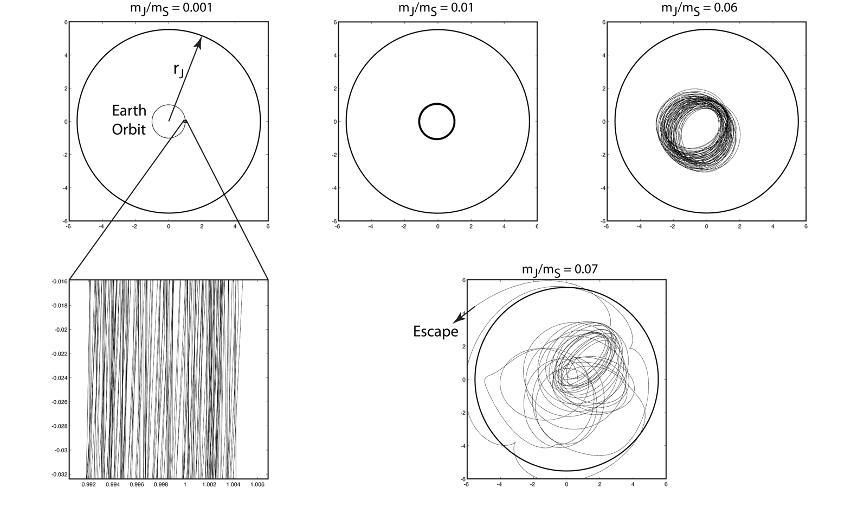
Chaos seems to rule our world. Weather events, natural disasters, economic volatility, empire building—all these contribute to the complexities that buffet our lives. It is no wonder that ancient man attributed the chaos to the gods or to the fates, infinitely far from anything we can comprehend as cause and effect. Yet there is a balm to soothe our wounds from the slings of life—Chaos Theory—if not to solve our problems, then at least to understand them.
Chaos Theory is the theory of complex systems governed by multiple factors that produce complicated outputs. The power of the theory is its ability recognize when the complicated outputs are not “random”, no matter how complicated they are, but are in fact determined by the inputs. Furthermore, chaos theory finds structures and patterns within the output—like the fractal structures known as “strange attractors”. These patterns not only are not random, but they tell us about the internal mechanics of the system, and they tell us where to look “on average” for the system behavior.
In other words, chaos theory tames the chaos, and we no longer need to blame gods or the fates.
Henri Poincare (1889)
The first glimpse of the inner workings of chaos was made by accident when Henri Poincaré responded to a mathematics competition held in honor of the King of Sweden. The challenge was to prove whether the solar system was absolutely stable, or whether there was a danger that one day the Earth would be flung from its orbit. Poincaré had already been thinking about the stability of dynamical systems so he wrote up his solution to the challenge and sent it in, believing that he had indeed proven that the solar system was stable.
His entry to the competition was the most convincing, so he was awarded the prize and instructed to submit the manuscript for publication. The paper was already at the printers and coming off the presses when Poincaré was asked by the competition organizer to check one last part of the proof which one of the reviewer’s had questioned relating to homoclinic orbits.
Fig. 1 A homoclinic orbit is an orbit in phase space that intersects itself.
To Poincaré’s horror, as he checked his results against the reviewer’s comments, he found that he had made a fundamental error, and in fact the solar system would never be stable. The problem that he had overlooked had to do with the way that orbits can cross above or below each other on successive passes, leading to a tangle of orbital trajectories that crisscrossed each other in a fine mesh. This is known as the “homoclinic tangle”: it was the first glimpse that deterministic systems could lead to unpredictable results. Most importantly, he had developed the first mathematical tools that would be needed to analyze chaotic systems—such as the Poincaré section—but nearly half a century would pass before these tools would be picked up again.
Poincaré paid out of his own pocket for the first printing to be destroyed and for the corrected version of his manuscript to be printed in its place [1]. No-one but the competition organizers and reviewers ever saw his first version. Yet it was when he was correcting his mistake that he stumbled on chaos for the first time, which is what posterity remembers him for. This little episode in the history of physics went undiscovered for a century before being brought to light by Barrow-Green in her 1997 book Poincaré and the Three Body Problem [2].
Fig. 2 Henri Poincaré’s homoclinic tangle from the Standard Map. (The picture on the right is the Poincaré crater on the moon). For more details, see my blog on Poincaré and his Homoclinic Tangle.
Cartwight and Littlewood (1945)
During World War II, self-oscillations and nonlinear dynamics became strategic topics for the war effort in England. High-power magnetrons were driving long-range radar, keeping Britain alert to Luftwaffe bombing raids, and the tricky dynamics of these oscillators could be represented as a driven van der Pol oscillator. These oscillators had been studied in the 1920’s by the Dutch physicist Balthasar van der Pol (1889–1959) when he was completing his PhD thesis at the University of Utrecht on the topic of radio transmission through ionized gases. van der Pol had built a short-wave triode oscillator to perform experiments on radio diffraction to compare with his theoretical calculations of radio transmission. Van der Pol’s triode oscillator was an engineering feat that produced the shortest wavelengths of the day, making van der Pol intimately familiar with the operation of the oscillator, and he proposed a general form of differential equation for the triode oscillator.
Fig. 3 Driven van der Pol oscillator equation.
Research on the radar magnetron led to theoretical work on driven nonlinear oscillators, including the discovery that a driven van der Pol oscillator could break up into wild and intermittent patterns. This “bad” behavior of the oscillator circuit (bad for radar applications) was the first discovery of chaotic behavior in man-made circuits.
These irregular properties of the driven van der Pol equation were studied by Mary- Lucy Cartwright (1990–1998) (the first woman to be elected a fellow of the Royal Society) and John Littlewood (1885–1977) at Cambridge who showed that the coexistence of two periodic solutions implied that discontinuously recurrent motion—in today’s parlance, chaos— could result, which was clearly undesirable for radar applications. The work of Cartwright and Littlewood [3] later inspired the work by Levinson and Smale as they introduced the field of nonlinear dynamics.
Fig. 4 Mary Cartwright
Andrey Kolmogorov (1954)
The passing of the Russian dictator Joseph Stalin provided a long-needed opening for Soviet scientists to travel again to international conferences where they could meet with their western colleagues to exchange ideas. Four Russian mathematicians were allowed to attend the 1954 International Congress of Mathematics (ICM) held in Amsterdam, the Netherlands. One of those was Andrey Nikolaevich Kolmogorov (1903 – 1987) who was asked to give the closing plenary speech. Despite the isolation of Russia during the Soviet years before World War II and later during the Cold War, Kolmogorov was internationally renowned as one of the greatest mathematicians of his day.
By 1954, Kolmogorov’s interests had spread into topics in topology, turbulence and logic, but no one was prepared for the topic of his plenary lecture at the ICM in Amsterdam. Kolmogorov spoke on the dusty old topic of Hamiltonian mechanics. He even apologized at the start for speaking on such an old topic when everyone had expected him to speak on probability theory. Yet, in the length of only half an hour he laid out a bold and brilliant outline to a proof that the three-body problem had an infinity of stable orbits. Furthermore, these stable orbits provided impenetrable barriers to the diffusion of chaotic motion across the full phase space of the mechanical system. The crucial consequences of this short talk were lost on almost everyone who attended as they walked away after the lecture, but Kolmogorov had discovered a deep lattice structure that constrained the chaotic dynamics of the solar system.
Kolmogorov’s approach used a result from number theory that provides a measure of how close an irrational number is to a rational one. This is an important question for orbital dynamics, because whenever the ratio of two orbital periods is a ratio of integers, especially when the integers are small, then the two bodies will be in a state of resonance, which was the fundamental source of chaos in Poincaré’s stability analysis of the three-body problem. After Komogorov had boldly presented his results at the ICM of 1954 [4], what remained was the necessary mathematical proof of Kolmogorov’s daring conjecture. This would be provided by one of his students, V. I. Arnold, a decade later. But before the mathematicians could settle the issue, an atmospheric scientist, using one of the first electronic computers, rediscovered Poincaré’s tangle, this time in a simplified model of the atmosphere.
Edward Lorenz (1963)
In 1960, with the help of a friend at MIT, the atmospheric scientist Edward Lorenz purchased a Royal McBee LGP-30 tabletop computer to make calculation of a simplified model he had derived for the weather. The McBee used 113 of the latest miniature vacuum tubes and also had 1450 of the new solid-state diodes made of semiconductors rather than tubes, which helped reduce the size further, as well as reducing heat generation. The McBee had a clock rate of 120 kHz and operated on 31-bit numbers with a 15 kB memory. Under full load it used 1500 Watts of power to run. But even with a computer in hand, the atmospheric equations needed to be simplified to make the calculations tractable. Lorenz simplified the number of atmospheric equations down to twelve, and he began programming his Royal McBee.
Progress was good, and by 1961, he had completed a large initial numerical study. One day, as he was testing his results, he decided to save time by starting the computations midway by using mid-point results from a previous run as initial conditions. He typed in the three-digit numbers from a paper printout and went down the hall for a cup of coffee. When he returned, he looked at the printout of the twelve variables and was disappointed to find that they were not related to the previous full-time run. He immediately suspected a faulty vacuum tube, as often happened. But as he looked closer at the numbers, he realized that, at first, they tracked very well with the original run, but then began to diverge more and more rapidly until they lost all connection with the first-run numbers. The internal numbers of the McBee had a precision of 6 decimal points, but the printer only printed three to save time and paper. His initial conditions were correct to a part in a thousand, but this small error was magnified exponentially as the solution progressed. When he printed out the full six digits (the resolution limit for the machine), and used these as initial conditions, the original trajectory returned. There was no mistake. The McBee was working perfectly.
At this point, Lorenz recalled that he “became rather excited”. He was looking at a complete breakdown of predictability in atmospheric science. If radically different behavior arose from the smallest errors, then no measurements would ever be accurate enough to be useful for long-range forecasting. At a more fundamental level, this was a break with a long-standing tradition in science and engineering that clung to the belief that small differences produced small effects. What Lorenz had discovered, instead, was that the deterministic solution to his 12 equations was exponentially sensitive to initial conditions (known today as SIC).
The more Lorenz became familiar with the behavior of his equations, the more he felt that the 12-dimensional trajectories had a repeatable shape. He tried to visualize this shape, to get a sense of its character, but it is difficult to visualize things in twelve dimensions, and progress was slow, so he simplified his equations even further to three variables that could be represented in a three-dimensional graph [5].
Fig. 5 Two-dimensional projection of the three-dimensional Lorenz Butterfly.
V. I. Arnold (1964)
Meanwhile, back in Moscow, an energetic and creative young mathematics student knocked on Kolmogorov’s door looking for an advisor for his undergraduate thesis. The youth was Vladimir Igorevich Arnold (1937 – 2010), who showed promise, so Kolmogorov took him on as his advisee. They worked on the surprisingly complex properties of the mapping of a circle onto itself, which Arnold filed as his dissertation in 1959. The circle map holds close similarities with the periodic orbits of the planets, and this problem led Arnold down a path that drew tantalizingly close to Kolmogorov’s conjecture on Hamiltonian stability. Arnold continued in his PhD with Kolmogorov, solving Hilbert’s 13th problem by showing that every function of n variables can be represented by continuous functions of a single variable. Arnold was appointed as an assistant in the Faculty of Mechanics and Mathematics at Moscow State University.
Arnold’s habilitation topic was Kolmogorov’s conjecture, and his approach used the same circle map that had played an important role in solving Hilbert’s 13th problem. Kolmogorov neither encouraged nor discouraged Arnold to tackle his conjecture. Arnold was led to it independently by the similarity of the stability problem with the problem of continuous functions. In reference to his shift to this new topic for his habilitation, Arnold stated “The mysterious interrelations between different branches of mathematics with seemingly no connections are still an enigma for me.” [6]
Arnold began with the problem of attracting and repelling fixed points in the circle map and made a fundamental connection to the theory of invariant properties of action-angle variables . These provided a key element in the proof of Kolmogorov’s conjecture. In late 1961, Arnold submitted his results to the leading Soviet physics journal—which promptly rejected it because he used forbidden terms for the journal, such as “theorem” and “proof”, and he had used obscure terminology that would confuse their usual physicist readership, terminology such as “Lesbesgue measure”, “invariant tori” and “Diophantine conditions”. Arnold withdrew the paper.
Arnold later incorporated an approach pioneered by Jurgen Moser [7] and published a definitive article on the problem of small divisors in 1963 [8]. The combined work of Kolmogorov, Arnold and Moser had finally established the stability of irrational orbits in the three-body problem, the most irrational and hence most stable orbit having the frequency of the golden mean. The term “KAM theory”, using the first initials of the three theorists, was coined in 1968 by B. V. Chirikov, who also introduced in 1969 what has become known as the Chirikov map (also known as the Standard map ) that reduced the abstract circle maps of Arnold and Moser to simple iterated functions that any student can program easily on a computer to explore KAM invariant tori and the onset of Hamiltonian chaos, as in Fig. 1 [9].
Fig. 6 The Chirikov Standard Map when the last stable orbits are about to dissolve for ε = 0.97.
Sephen Smale (1967)
Stephen Smale was at the end of a post-graduate fellowship from the National Science Foundation when he went to Rio to work with Mauricio Peixoto. Smale and Peixoto had met in Princeton in 1960 where Peixoto was working with Solomon Lefschetz (1884 – 1972) who had an interest in oscillators that sustained their oscillations in the absence of a periodic force. For instance, a pendulum clock driven by the steady force of a hanging weight is a self-sustained oscillator. Lefschetz was building on work by the Russian Aleksandr A. Andronov (1901 – 1952) who worked in the secret science city of Gorky in the 1930’s on nonlinear self-oscillations using Poincaré’s first return map. The map converted the continuous trajectories of dynamical systems into discrete numbers, simplifying problems of feedback and control.
The central question of mechanical control systems, even self-oscillating systems, was how to attain stability. By combining approaches of Poincaré and Lyapunov, as well as developing their own techniques, the Gorky school became world leaders in the theory and applications of nonlinear oscillations. Andronov published a seminal textbook in 1937 The Theory of Oscillations with his colleagues Vitt and Khaykin, and Lefschetz had obtained and translated the book into English in 1947, introducing it to the West. When Peixoto returned to Rio, his interest in nonlinear oscillations captured the imagination of Smale even though his main mathematical focus was on problems of topology. On the beach in Rio, Smale had an idea that topology could help prove whether systems had a finite number of periodic points. Peixoto had already proven this for two dimensions, but Smale wanted to find a more general proof for any number of dimensions.
Norman Levinson (1912 – 1975) at MIT became aware of Smale’s interests and sent off a letter to Rio in which he suggested that Smale should look at Levinson’s work on the triode self-oscillator (a van der Pol oscillator), as well as the work of Cartwright and Littlewood who had discovered quasi-periodic behavior hidden within the equations. Smale was puzzled but intrigued by Levinson’s paper that had no drawings or visualization aids, so he started scribbling curves on paper that bent back upon themselves in ways suggested by the van der Pol dynamics. During a visit to Berkeley later that year, he presented his preliminary work, and a colleague suggested that the curves looked like strips that were being stretched and bent into a horseshoe.
Smale latched onto this idea, realizing that the strips were being successively stretched and folded under the repeated transformation of the dynamical equations. Furthermore, because dynamics can move forward in time as well as backwards, there was a sister set of horseshoes that were crossing the original set at right angles. As the dynamics proceeded, these two sets of horseshoes were repeatedly stretched and folded across each other, creating an infinite latticework of intersections that had the properties of the Cantor set. Here was solid proof that Smale’s original conjecture was wrong—the dynamics had an infinite number of periodicities, and they were nested in self-similar patterns in a latticework of points that map out a Cantor-like set of points. In the two-dimensional case, shown in the figure, the fractal dimension of this lattice is D = ln4/ln3 = 1.26, somewhere in dimensionality between a line and a plane. Smale’s infinitely nested set of periodic points was the same tangle of points that Poincaré had noticed while he was correcting his King Otto Prize manuscript. Smale, using modern principles of topology, was finally able to put rigorous mathematical structure to Poincaré’s homoclinic tangle. Coincidentally, Poincaré had launched the modern field of topology, so in a sense he sowed the seeds to the solution to his own problem.
Fig. 7 The horseshoe takes regions of phase space and stretches and folds them over and over to create a lattice of overlapping trajectories.
Ruelle and Takens (1971)
The onset of turbulence was an iconic problem in nonlinear physics with a long history and a long list of famous researchers studying it. As far back as the Renaissance, Leonardo da Vinci had made detailed studies of water cascades, sketching whorls upon whorls in charcoal in his famous notebooks. Heisenberg, oddly, wrote his PhD dissertation on the topic of turbulence even while he was inventing quantum mechanics on the side. Kolmogorov in the 1940’s applied his probabilistic theories to turbulence, and this statistical approach dominated most studies up to the time when David Ruelle and Floris Takens published a paper in 1971 that took a nonlinear dynamics approach to the problem rather than statistical, identifying strange attractors in the nonlinear dynamical Navier-Stokes equations [10]. This paper coined the phrase “strange attractor”. One of the distinct characteristics of their approach was the identification of a bifurcation cascade. A single bifurcation means a sudden splitting of an orbit when a parameter is changed slightly. In contrast, a bifurcation cascade was not just a single Hopf bifurcation, as seen in earlier nonlinear models, but was a succession of Hopf bifurcations that doubled the period each time, so that period-two attractors became period-four attractors, then period-eight and so on, coming fast and faster, until full chaos emerged. A few years later Gollub and Swinney experimentally verified the cascade route to turbulence , publishing their results in 1975 [11].
Fig. 8 Bifurcation cascade of the logistic map.
Feigenbaum (1978)
In 1976, computers were not common research tools, although hand-held calculators now were. One of the most famous of this era was the Hewlett-Packard HP-65, and Feigenbaum pushed it to its limits. He was particularly interested in the bifurcation cascade of the logistic map [12]—the way that bifurcations piled on top of bifurcations in a forking structure that showed increasing detail at increasingly fine scales. Feigenbaum was, after all, a high-energy theorist and had overlapped at Cornell with Kenneth Wilson when he was completing his seminal work on the renormalization group approach to scaling phenomena. Feigenbaum recognized a strong similarity between the bifurcation cascade and the ideas of real-space renormalization where smaller and smaller boxes were used to divide up space.
One of the key steps in the renormalization procedure was the need to identify a ratio of the sizes of smaller structures to larger structures. Feigenbaum began by studying how the bifurcations depended on the increasing growth rate. He calculated the threshold values rm for each of the bifurcations, and then took the ratios of the intervals, comparing the previous interval (rm-1 – rm-2) to the next interval (rm – rm-1). This procedure is like the well-known method to calculate the golden ratio = 1.61803 from the Fibonacci series, and Feigenbaum might have expected the golden ratio to emerge from his analysis of the logistic map. After all, the golden ratio has a scary habit of showing up in physics, just like in the KAM theory. However, as the bifurcation index m increased in Feigenbaum’s study, this ratio settled down to a limiting value of 4.66920. Then he did what anyone would do with an unfamiliar number that emerges from a physical calculation—he tried to see if it was a combination of other fundamental numbers, like pi and Euler’s constant e, and even the golden ratio. But none of these worked. He had found a new number that had universal application to chaos theory [13].
Fig. 9 The ratio of the limits of successive cascades leads to a new universal number (the Feigenbaum number).
Gleick (1987)
By the mid-1980’s, chaos theory was seeping in to a broadening range of research topics that seemed to span the full breadth of science, from biology to astrophysics, from mechanics to chemistry. A particularly active group of chaos practitioners were J. Doyn Farmer, James Crutchfield, Norman Packard and Robert Shaw who founded the Dynamical Systems Collective at the University of California, Santa Cruz. One of the important outcomes of their work was a method to reconstruct the state space of a complex system using only its representative time series [14]. Their work helped proliferate the techniques of chaos theory into the mainstream. Many who started using these techniques were only vaguely aware of its long history until the science writer James Gleick wrote a best-selling history of the subject that brought chaos theory to the forefront of popular science [15]. And the rest, as they say, is history.
By David D. Nolte, April 3, 2024
References
[1] Poincaré, H. and D. L. Goroff (1993). New methods of celestial mechanics. Edited and introduced by Daniel L. Goroff. New York, American Institute of Physics.
[2] J. Barrow-Green, Poincaré and the three body problem (London Mathematical Society, 1997).
[3] Cartwright,M.L.andJ.E.Littlewood(1945).“Onthenon-lineardifferential equation of the second order. I. The equation y′′ − k(1 – yˆ2)y′ + y = bλk cos(λt + a), k large.” Journal of the London Mathematical Society 20: 180–9. Discussed in Aubin, D. and A. D. Dalmedico (2002). “Writing the History of Dynamical Systems and Chaos: Longue DurÈe and Revolution, Disciplines and Cultures.” Historia Mathematica, 29: 273.
[4] Kolmogorov, A. N., (1954). “On conservation of conditionally periodic motions for a small change in Hamilton’s function.,” Dokl. Akad. Nauk SSSR (N.S.), 98: 527–30.
[5] Lorenz, E. N. (1963). “Deterministic Nonperiodic Flow.” Journal of the Atmo- spheric Sciences 20(2): 130–41.
[6] Arnold,V.I.(1997).“From superpositions to KAM theory,”VladimirIgorevich Arnold. Selected, 60: 727–40.
[7] Moser, J. (1962). “On Invariant Curves of Area-Preserving Mappings of an Annulus.,” Nachr. Akad. Wiss. Göttingen Math.-Phys, Kl. II, 1–20.
[8] Arnold, V. I. (1963). “Small denominators and problems of the stability of motion in classical and celestial mechanics (in Russian),” Usp. Mat. Nauk., 18: 91–192,; Arnold, V. I. (1964). “Instability of Dynamical Systems with Many Degrees of Freedom.” Doklady Akademii Nauk Sssr 156(1): 9.
[9] Chirikov, B. V. (1969). Research concerning the theory of nonlinear resonance andstochasticity. Institute of Nuclear Physics, Novosibirsk. 4. Note: The Standard Map Jn+1 =Jn +εsinθn θn+1 =θn +Jn+1 is plotted in Fig. 3.31 in Nolte, Introduction to Modern Dynamics (2015) on p. 139. For small perturbation ε, two fixed points appear along the line J = 0 corresponding to p/q = 1: one is an elliptical point (with surrounding small orbits) and the other is a hyperbolic point where chaotic behavior is first observed. With increasing perturbation, q elliptical points and q hyperbolic points emerge for orbits with winding numbers p/q with small denominators (1/2, 1/3, 2/3 etc.). Other orbits with larger q are warped by the increasing perturbation but are not chaotic. These orbits reside on invariant tori, known as the KAM tori, that do not disintegrate into chaos at small perturbation. The set of KAM tori is a Cantor-like set with non- zero measure, ensuring that stable behavior can survive in the presence of perturbations, such as perturbation of the Earth’s orbit around the Sun by Jupiter. However, with increasing perturbation, orbits with successively larger values of q disintegrate into chaos. The last orbits to survive in the Standard Map are the golden mean orbits with p/q = φ–1 and p/q = 2–φ. The critical value of the perturbation required for the golden mean orbits to disintegrate into chaos is surprisingly large at εc = 0.97.
[10] Ruelle,D. and F.Takens (1971).“OntheNatureofTurbulence.”Communications in Mathematical Physics 20(3): 167–92.
[11] Gollub, J. P. and H. L. Swinney (1975). “Onset of Turbulence in a Rotating Fluid.” Physical Review Letters, 35(14): 927–30.
[12] May, R. M. (1976). “Simple Mathematical-Models with very complicated Dynamics.” Nature, 261(5560): 459–67.
[13] M. J. Feigenbaum, “Quantitative Universality for a Class of Nnon-linear Transformations,” Journal of Statistical Physics 19, 25-52 (1978).
[14] Packard, N.; Crutchfield, J. P.; Farmer, J. Doyne; Shaw, R. S. (1980). “Geometry from a Time Series”. Physical Review Letters. 45 (9): 712–716.
Fractals, those telescoping self-similar filigree meshes that marry mathematics and art, have become so mainstream, that they are even mentioned in the theme song of Disney’s 2013 mega-hit, Frozen.
My power flurries through the air into the ground My soul is spiraling in frozen fractals all around And one thought crystallizes like an icy blast I’m never going back, the past is in the past
Let it Go, by Idina Menzel (Frozen, Disney 2013)
But not all fractals are cut from the same cloth. Some are thin and some are fat. The thin ones are the ones we know best, adorning the cover of books and magazines. But the fat ones may be more common and may play important roles, such as in the stability of celestial orbits in a many-planet neighborhood, or in the stability and structure of Saturn’s rings.
To get a handle on fat fractals, we will start with a familiar thin one, the zero-measure Cantor set.
The Zero-Measure Cantor Set
The famous one-third Cantor set is often the first fractal that you encounter in any introduction to fractals. (See my blog on a short history of fractals.) It lives on a one-dimensional line, and its iterative construction is intuitive and simple.
Start with a long thin bar of unit length. Then remove the middle third, leaving the endpoints. This leaves two identical bars of one-third length each. Next, remove the open middle third of each of these, again leaving the endpoints, leaving behind section pairs of one-nineth length. Then repeat ad infinitum. The points of the line that remain–all those segment endpoints–are the Cantor set.
Fig. 1 Construction of the 1/3 Cantor set by removing 1/3 segments at each level, and leaving the endpoints of each segment. The resulting set is a dust of points with a fractal dimension D = ln(2)/ln(3) = 0.6309.
The Cantor set has a fractal dimension that is easily calculated by noting that at each stage there are two elements (N = 2) that divided by three in size (b = 3). The fractal dimension is then
It is easy to prove that the collection of points of the Cantor set have no length because all of the length was removed.
For instance, at the first level, one third of the length was removed. At the second level, two segments of one-nineth length were removed. At the third level, four segments of one-twenty-sevength length were removed, and so on. Mathematically, this is
The infinite series in the brackets is a binomial series with the simple solution
Therefore, all the length has been removed, and none is left to the Cantor set, which is simply a collection of all the endpoints of all the segments that were removed.
The Cantor set is said to have a Lebesgue measure of zero. It behaves as a dust of isolated points.
A close relative of the Cantor set is the Sierpinski Carpet which is the two-dimensional analog. It begins with a square of unit side, then the middle third is removed (one nineth of the three-by-three array of square of one-third side), and so on.
Fig. 2 A regular Sierpinski Carpet with fractal dimension D = ln(8)/ln(3) = 1.8928.
The resulting Sierpinski Carpet has zero Lebesgue measure, just like the Cantor dust, because all the area has been removed.
There are also random Sierpinski Carpets as the sub-squares are removed from random locations.
Fig. 3 A random Sierpinski Carpet with fractal dimension D = ln(8)/ln(3) = 1.8928.
These fractals are “thin”, so-called because they are dusts with zero measure.
But the construction was constructed just so, such that the sum over all the removed sub-lengths summed to unity. What if less material had been taken at each step? What happens?
Fat Fractals
Instead of taking one-third of the original length, take instead one-fourth. But keep the one-third scaling level-to-level, as for the original Cantor Set.
Fig. 4 A “fat” Cantor fractal constructed by removing 1/4 of a segment at each level instead of 1/3.
The total length removed is
Therefore, three fourths of the length was removed, leaving behind one fourth of the material. Not only that, but the material left behind is contiguous—solid lengths. At each level, a little bit of the original bar remains, and still remains at the next level and the next. Therefore, it is said to have a Lebesgue measure of unity. This construction leads to a “fat” fractal.
Fig. 5 Fat Cantor fractal showing the original Cantor 1/3 set (in black) and the extra contiguous segments (in red) that give the set a Lebesgue measure equal to one.
Looking at Fig. 5, it is clear that the original Cantor dust is still present as the black segments interspersed among the red parts of the bar that are contiguous. But when two sets are added that have different “dimensions”, then the combined set has the larger dimension of the two, which is one-dimensional in this case. The fat Cantor set is one dimensional. One can still study its scaling properties, leading to another type of dimension known as an exterior measure [1], but where do such fat fractals occur? Why do they matter?
One answer is that they lie within the oddly named “Arnold Tongues” that arise in the study of synchronization and resonance connected to the stability of the solar system and the safety of its inhabitants.
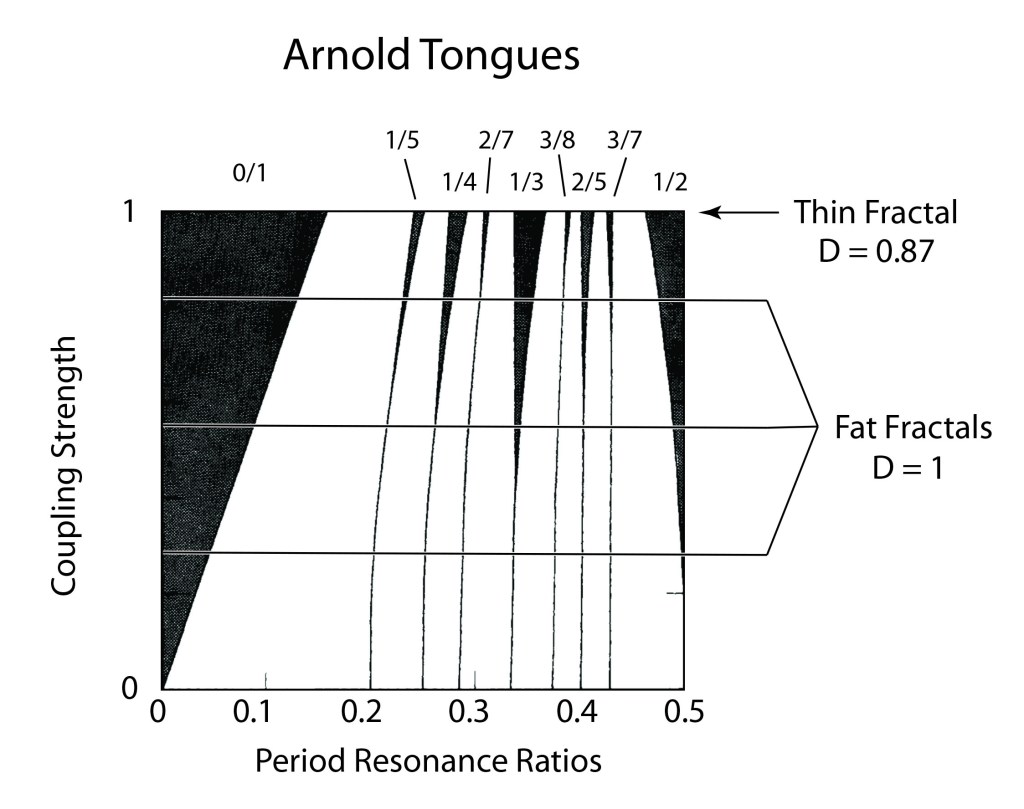
Arnold Tongues
The study of synchronization explores and explains how two or more non-identical oscillators can lock themselves onto a common shared oscillation. For two systems to synchronize requires autonomous oscillators (like planetary orbits) with a period-dependent interaction (like gravity). Such interactions are “resonant” when the periods of the two orbits are integer ratios of each other, like 1:2 or 2:3. Such resonances ensure that there is a periodic forcing caused by the interaction that is some multiple of the orbital period. Think of tapping a rotating bicycle wheel twice per cycle or three times per cycle. Even if you are a little off in your timing, you can lock the tire rotation rate to a multiple of your tapping frequency. But if you are too far off on your timing, then the wheel will turn independently of your tapping.
Because rational ratios of integers are plentiful, there can be an intricate interplay between locked frequencies and unlocked frequencies. When the rotation rate is close to a resonance, then the wheel can frequency-lock to the tapping. Plotting the regions where the wheel synchronizes or not as a function of the frequency ratio and also as a function of the strength of the tapping leads to one of the iconic images of nonlinear dynamics: the Arnold tongue diagram.
Fig. 6 Arnold tongue diagram, showing the regions of frequency locking (black) at rational resonances as a function of coupling strength. At unity coupling strength, the set outside frequency-locked regions is fractal with D = 0.87. For all smaller coupling, a set along a horizontal is a fat fractal with topological dimension D = 1. The white regions are “ergodic”, as the phase of the oscillator runs through all possible values.
The Arnold tongues in Fig. 6 are the frequency locked regions (black) as a function of frequency ratio and coupling strength g. The black regions correspond to rational ratios of frequencies. For g = 1, the set outside frequency-locked regions (the white regions are “ergodic”, as the phase of the oscillator runs through all possible values) is a thin fractal with D = 0.87. For g < 1, the sets outside the frequency locked regions along a horizontal (at constant g) are fat fractals with topological dimension D = 1. For fat fractals, the fractal dimension is irrelevant, and another scaling exponent takes on central importance.
The Lebesgue measure μ of the ergodic regions (the regions that are not frequency locked) is a function of the coupling strength varying from μ = 1 at g = 0 to μ = 0 at g = 1. When the pattern is coarse-grained at a scale ε, then the scaling of a fat fractal is
where β is the scaling exponent that characterizes the fat fractal.
From numerical studies [2] there is strong evidence that β = 2/3 for the fat fractals of Arnold Tongues.
The Rings of Saturn
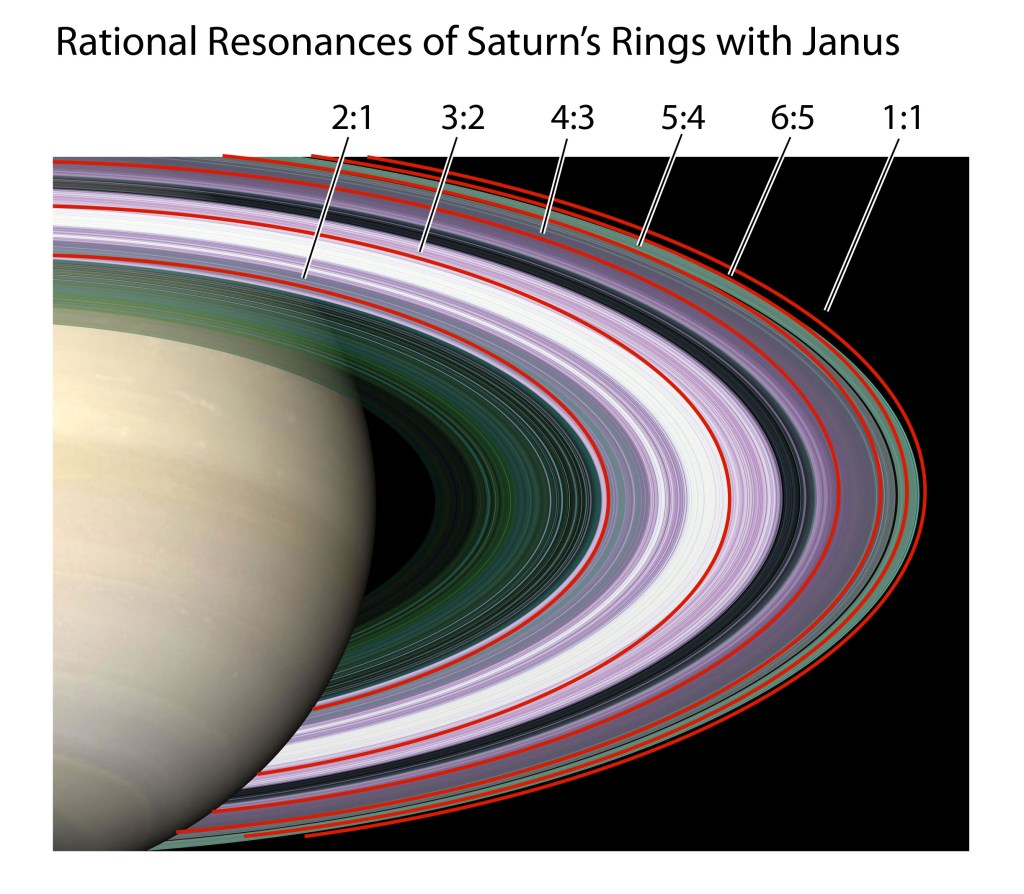
Arnold Tongues arise in KAM theory on the stability of the solar system (See my blog on KAM and how number theory protects us from the chaos of the cosmos). Fortunately, Jupiter is the largest perturbation to Earth’s orbit, but its influence, while non-zero, is not enough to seriously affect our stability. However, there is a part of the solar system where rational resonances are not only large but dominant: Saturn’s rings.
Saturn’s rings are composed of dust and ice particles that orbit Saturn with a range of orbital periods. When one of these periods is a rational fraction of the orbital period of a moon, then a resonance condition is satisfied. Saturn has many moons, producing highly corrugated patterns in Saturn’s rings at rational resonances of the periods.
Fig. 7 A close up of Saturn’s rings shows a highly detailed set of bands. Particles at a given radius have a given period (set by Kepler’s third law). When the period of dust particles in the ring are an integer ratio of the period of a “shepherd moon”, then a resonance can drive density rings. [See image reference.]
The moons Janus and Epithemeus share an orbit around Saturn in a rare 1:1 resonance in which they swap positions every four years. Their combined gravity excites density ripples in Saturn’s rings, photographed by the Cassini spacecraft and shown in Fig. 8.
Fig. 8 Cassini spacecraft photograph of density ripples in Saturns rings caused by orbital resonance with the pair of moons Janus and Epithemeus.
One Canadian astronomy group converted the resonances of the moon Janus into a musical score to commenorate Cassini’s final dive into the planet Saturn in 2017. The Janus resonances are shown in Fig. 9 against the pattern of Saturn’s rings.
Fig. 7 Rational resonances for subrings of Saturn relative to its moon Janus.
Saturn’s rings, orbital resonances, Arnold tongues and fat fractals provide a beautiful example of the power of dynamics to create structure, and the primary role that structure plays in deciphering the physics of complex systems.
By David D. Nolte, Nov. 28, 2023
References:
[1] C. Grebogi, S. W. McDonald, E. Ott, and J. A. Yorke, “EXTERIOR DIMENSION OF FAT FRACTALS,” Physics Letters A 110, 1-4 (1985).
[2] R. E. Ecke, J. D. Farmer, and D. K. Umberger, “Scaling of the Arnold tongues,” Nonlinearity 2, 175-196 (1989).
Read more in Books by David Nolte at Oxford University Press
When our son was ten years old, he came home from a town fair in Battleground, Indiana, with an unwanted pet—a goldfish in a plastic bag. The family rushed out to buy a fish bowl and food and plopped the golden-red animal into it. In three days, it was dead!
It turns out that you can’t just put a gold fish in a fish bowl. When it metabolizes its food and expels its waste, it builds up toxic levels of ammonia unless you add filters or plants or treat the water with chemicals. In the end, the goldfish died because it was asphyxiated by its own pee.
It’s a basic rule—don’t pee in your own fish bowl.
The same can be said for humans living on the surface of our planet. Polluting the atmosphere with our wastes cannot be a good idea. In the end it will kill us. The atmosphere may look vast—the fish bowl was a big one—but it is shocking how thin it is.
Turn on your Apple TV, click on the screen saver, and you are skimming over our planet on the dark side of the Earth. Then you see a thin blue line extending over the limb of the dark disc. Hold! That thin blue line! That is our atmosphere! Is it really so thin?
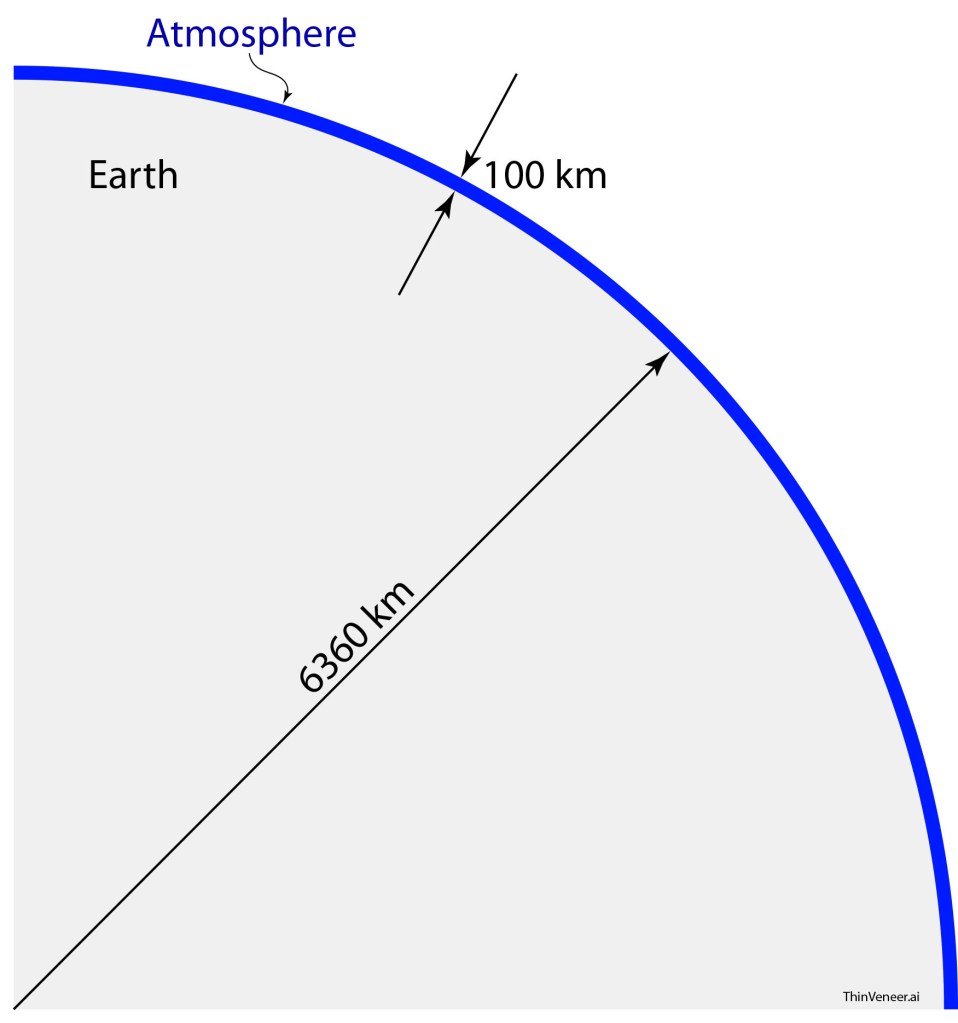
When you look upwards on a clear sunny day, the atmosphere seems like it goes on forever. It doesn’t. It is a thin veneer on the surface of the Earth barely one percent of the Earth’s radius. The Earth’s atmosphere is frighteningly thin.
Fig. 1 A thin veneer of atmosphere paints the surface of the Earth. The radius of the Earth is 6360 km, and the thickness of the atmosphere is 100 km, which is a bit above 1 percent of the radius.
Consider Mars. It’s half the size of Earth, yet it cannot hold on to an atmosphere even 1/100th the thickness of ours. When Mars first formed, it had an atmosphere not unlike our own, but through the eons its atmosphere has wafted away irretrievably into space.
An atmosphere is a precious fragile thing for a planet. It gives life and it gives protection. It separates us from the deathly cold of space, holding heat like a blanket. That heat has served us well over the eons, allowing water to stay liquid and allowing life to arise on Earth. But too much of a good thing is not a good thing.
Common Sense
If the fluid you are bathed in gives you life, then don’t mess with it. Don’t run your car in the garage while you are working in it. Don’t use a charcoal stove in an enclosed space. Don’t dump carbon dioxide into the atmosphere because it alsois an enclosed space.
At the end of winter, as the warm spring days get warmer, you take the winter blanket off your bed because blankets hold in heat. The thicker the blanket, the more heat it holds in. Common sense tells you to reduce the thickness of the blanket if you don’t want to get too warm. Carbon dioxide in the atmosphere acts like a blanket. If we don’t want the Earth to get too warm, then we need to limit the thickness of the blanket.
Without getting into the details of any climate change model, common sense already tells us what we should do. Keep the atmosphere clean and stable (Don’t’ pee in our fishbowl) and limit the amount of carbon dioxide we put into it (Don’t let the blanket get too thick).
Some Atmospheric Facts
Here are some facts about the atmosphere, about the effect humans have on it, and about the climate:
Fact 1. Humans have increased the amount of carbon dioxide in the atmosphere by 45% since 1850 (the beginning of the industrial age) and by 30% since just 1960.
Fact 2. Carbon dioxide in the atmosphere prevents some of the heat absorbed from the Sun to re-radiate out to space. More carbon dioxide stores more heat.
Fact 3. Heat added to the Earth’s atmosphere increases its temperature. This is a law of physics.
Fact 4. The Earth’s average temperature has risen by 1.2 degrees Celsius since 1850 and 0.8 degrees of that has been just since 1960, so the effect is accelerating.
These facts are indisputable. They hold true regardless of whether there is a Republican or a Democrat in the White House or in control of Congress.
There is another interesting observation which is not so direct, but may hold a harbinger for the distant future: The last time the Earth was 3 degrees Celsius warmer than it is today was during the Pliocene when the sea level was tens of meters higher. If that sea level were to occur today, all of Delaware, most of Florida, half of Louisiana and the entire east coast of the US would be under water, including Houston, Miami, New Orleans, Philadelphia and New York City. There are many reasons why this may not be an immediate worry. The distribution of water and ice now is different than in the Pliocene, and the effect of warming on the ice sheets and water levels could take centuries. Within this century, the amount of sea level rise is likely to be only about 1 meter, but accelerating after that.
Fig. 2 The east coast of the USA for a sea level 30 meters higher than today. All of Delaware, half of Louisiana, and most of Florida are under water. Reasonable projections show only a 1 meter sea level rise by 2100, but accelerating after that. From https://www.youtube.com/watch?v=G2x1bonLJFA
Balance and Feedback
It is relatively easy to create a “rule-of-thumb” model for the Earth’s climate (see Ref. [2]). This model is not accurate, but it qualitatively captures the basic effects of climate change and is a good way to get an intuitive feeling for how the Earth responds to changes, like changes in CO2 or to the amount of ice cover. It can also provide semi-quantitative results, so that relative importance of various processes or perturbations can be understood.
The model is a simple energy balance statement: In equilibrium, as much energy flows into the Earth system as out.
This statement is both simple and immediately understandable. But then the work starts as we need to pin down how much energy is flowing in and how much is flowing out. The energy flowing in comes from the sun, and the energy flowing out comes from thermal radiation into space.
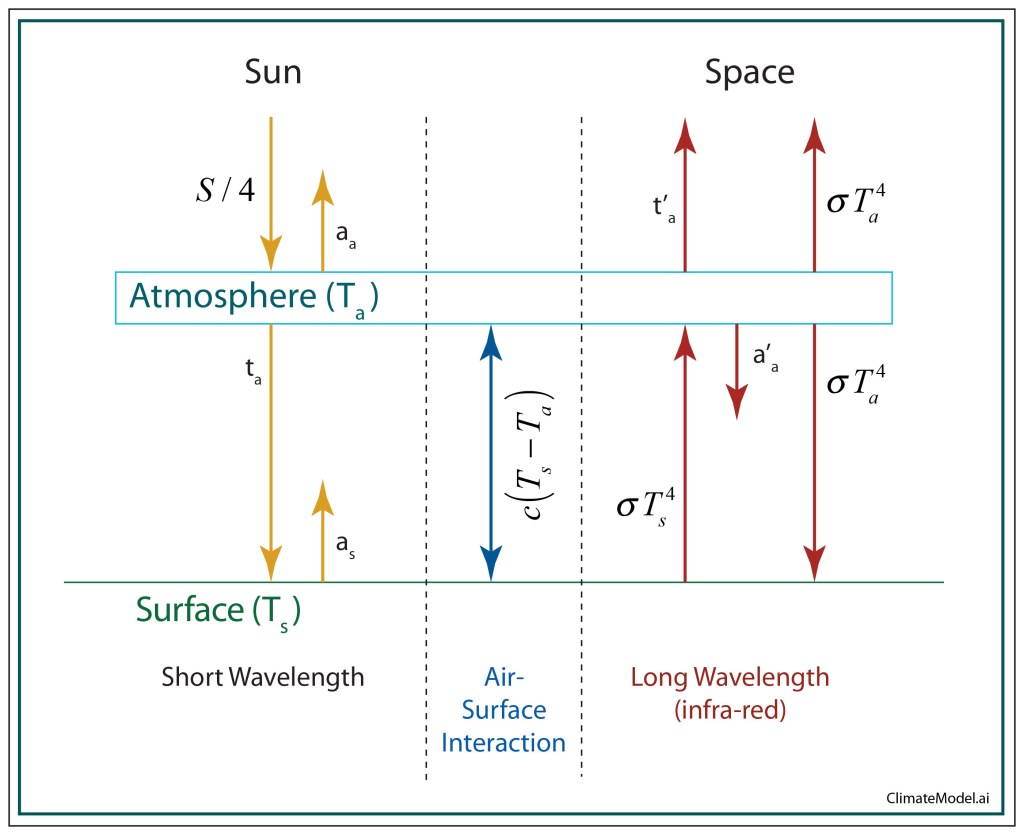
We also need to separate the Earth system into two components: the surface and the atmosphere. These are two very different things that have two different average temperatures. In addition, the atmosphere transmits sunlight to the surface, unless clouds reflect it back into space. And the Earth radiates thermally into space, unless clouds or carbon dioxide layers reflect it back to the surface.
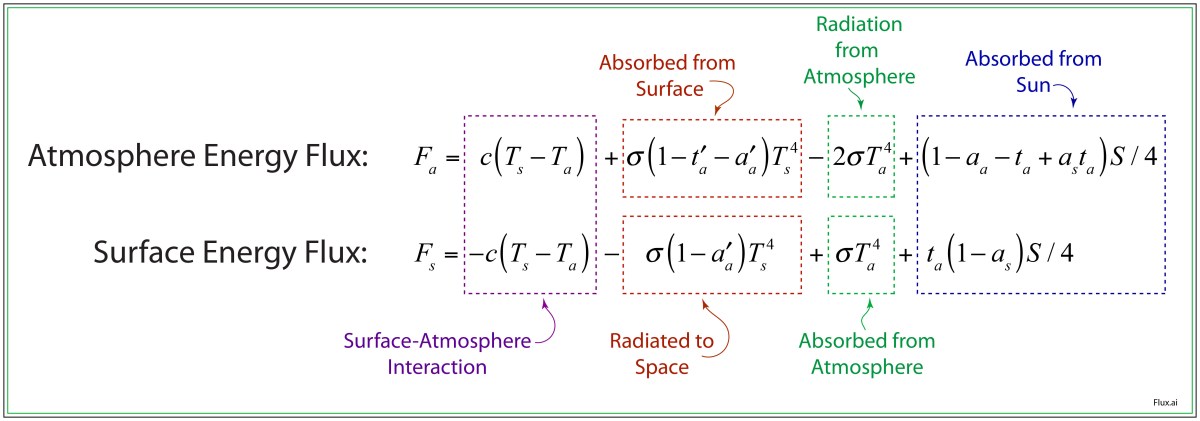
The energy fluxes are shown in the diagram in Fig. 3 for the 4-component system: Sun, Surface, Atmosphere, and Space. The light from the sun, mostly in the visible range of the spectrum, is partially absorbed by the atmosphere and partially transmitted and reflected. The transmitted portion is partially absorbed and partially reflected by the surface. The heat of the Earth is radiated at long wavelengths to the atmosphere, where it is partially transmitted out into space, but also partially reflected by the fraction a’a which is the blanket effect. In addition, the atmosphere itself radiates in equal parts to the surface and into outer space. On top of all of these radiative processes, there is also non-radiative convective interaction between the atmosphere and the surface.
Fig. 3 Energy flux model for a simple climate model with four interacting systems: the Sun, the Atmosphere, the Earth and Outer Space.
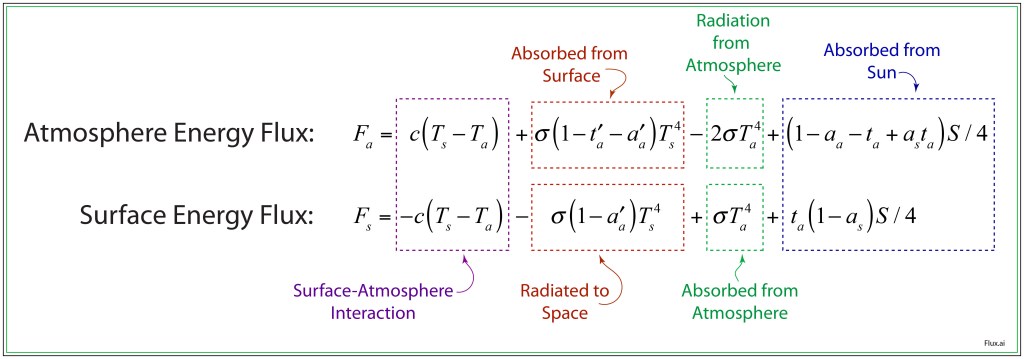
These processes are captured by two energy flux equations, one for the atmosphere and one for the surface, in Fig. 4. The individual contributions from Fig. 3 are annotated in each case. In equilibrium, each flux equals zero, which can then be used to solve for the two unknowns: Ts0 and Ta0: the surface and atmosphere temperatures.
Fig. 4 Energy-balance model of the Earth’s atmosphere for a simple climate approximation.
After the equilibrium temperatures Ts0 and Ta0 are found, they go into a set of dynamic response equations that governs how deviations in the temperatures relax back to the equilibrium values. These relaxation equations are
where ks and ka are the relaxation rates for the surface and atmosphere. These can be quite slow, in the range of a century. For illustration, we can take ks = 1/75 years and ka = 1/25 years. The equilibrium temperatures for the surface and atmosphere differ by about 50 degrees Celsius, with Ts = 289 K and Ta = 248 K. These are rough averages over the entire planet. The solar constant is S = 1.36×103 W/m2, the Stefan-Boltzman constant is σ = 5.67×10-8 W/m2/K4, and the convective interaction constant is c = 2.5 W m-2 K-1. Other parameters are given in Table I.
Short Wavelength
Long Wavelength
as = 0.11
ts = 0.53
t’a = 0.06
aa = 0.30
a’a = 0.31
The relaxation equations are in the standard form of a mathematical “flow” (see Ref. [1]) and the solutions are plotted as a phase-space portrait in Fig. 5 as a video of the flow as the parameters in Table I shift because of the addition of greenhouse gases to the atmosphere. The video runs from the year 1850 (the dawn of the industrial age) through to the year 2060 about 40 years from now.
Fig. 5 Video of the phase space flow of the Surface-Atmosphere system for increasing year. The flow vectors and flow lines are the relaxation to equilibrium for temperature deviations. The change in equilibrium over the years is from increasing blanket effects in the atmosphere caused by greenhouse gases.
The scariest part of the video is how fast it accelerates. From 1850 to 1950 there is almost no change, but then it accelerates, faster and faster, reflecting the time-lag in temperature rise in response to increased greenhouse gases.
What if the Models are Wrong? Russian Roulette
Now come the caveats.
This model is just for teaching purposes, not for any realistic modeling of climate change. It captures the basic physics, and it provides a semi-quantitative set of parameters that leads to roughly accurate current temperatures. But of course, the biggest elephant in the room is that it averages over the entire planet, which is a very crude approximation.
It does get the basic facts correct, though, showing an alarming trend in the rise in average temperatures with the temperature rising by 3 degrees by 2060.
The professionals in this business have computer models that are orders of magnitude more more accurate than this one. To understand the details of the real climate models, one needs to go to appropriate resources, like this NOAA link, this NASA link, this national climate assessment link, and this government portal link, among many others.
One of the frequent questions that is asked is: What if these models are wrong? What if global warming isn’t as bad as these models say? The answer is simple: If they are wrong, then the worst case is that life goes on. If they are right, then in the worst case life on this planet may end.
It’s like playing Russian Roulette. If just one of the cylinders on the revolver has a live bullet, do you want to pull the trigger?
Matlab Code
function flowatmos.m
mov_flag = 1;
if mov_flag == 1
moviename = 'atmostmp';
aviobj = VideoWriter(moviename,'MPEG-4');
aviobj.FrameRate = 12;
open(aviobj);
end
Solar = 1.36e3; % Solar constant outside atmosphere [J/sec/m2]
sig = 5.67e-8; % Stefan-Boltzman constant [W/m2/K4]
% 1st-order model of Earth + Atmosphere
ta = 0.53; % (0.53)transmissivity of air
tpa0 = 0.06; % (0.06)primes are for thermal radiation
as0 = 0.11; % (0.11)
aa0 = 0.30; % (0.30)
apa0 = 0.31; % (0.31)
c = 2.5; % W/m2/K
xrange = [287 293];
yrange = [247 251];
rngx = xrange(2) - xrange(1);
rngy = yrange(2) - yrange(1);
[X,Y] = meshgrid(xrange(1):0.05:xrange(2), yrange(1):0.05:yrange(2));
smallarrow = 1;
Delta0 = 0.0000009;
for tloop =1:80
Delta = Delta0*(exp((tloop-1)/8)-1); % This Delta is exponential, but should become more linear over time
date = floor(1850 + (tloop-1)*(2060-1850)/79);
[x,y] = f5(X,Y);
clf
hold off
eps = 0.002;
for xloop = 1:11
xs = xrange(1) +(xloop-1)*rngx/10 + eps;
for yloop = 1:11
ys = yrange(1) +(yloop-1)*rngy/10 + eps;
streamline(X,Y,x,y,xs,ys)
end
end
hold on
[XQ,YQ] = meshgrid(xrange(1):1:xrange(2),yrange(1):1:yrange(2));
smallarrow = 1;
[xq,yq] = f5(XQ,YQ);
quiver(XQ,YQ,xq,yq,.2,'r','filled')
hold off
axis([xrange(1) xrange(2) yrange(1) yrange(2)])
set(gcf,'Color','White')
fun = @root2d;
x0 = [0 -40];
x = fsolve(fun,x0);
Ts = x(1) + 288
Ta = x(2) + 288
hold on
rectangle('Position',[Ts-0.05 Ta-0.05 0.1 0.1],'Curvature',[1 1],'FaceColor',[1 0 0],'EdgeColor','k','LineWidth',2)
posTs(tloop) = Ts;
posTa(tloop) = Ta;
plot(posTs,posTa,'k','LineWidth',2);
hold off
text(287.5,250.5,strcat('Date = ',num2str(date)),'FontSize',24)
box on
xlabel('Surface Temperature (oC)','FontSize',24)
ylabel('Atmosphere Temperature (oC)','FontSize',24)
hh = figure(1);
pause(0.01)
if mov_flag == 1
frame = getframe(hh);
writeVideo(aviobj,frame);
end
end % end tloop
if mov_flag == 1
close(aviobj);
end
function F = root2d(xp) % Energy fluxes
x = xp + 288;
feedfac = 0.001; % feedback parameter
apa = apa0 + feedfac*(x(2)-248) + Delta; % Changes in the atmospheric blanket
tpa = tpa0 - feedfac*(x(2)-248) - Delta;
as = as0 - feedfac*(x(1)-289);
F(1) = c*(x(1)-x(2)) + sig*(1-apa)*x(1).^4 - sig*x(2).^4 - ta*(1-as)*Solar/4;
F(2) = c*(x(1)-x(2)) + sig*(1-tpa - apa)*x(1).^4 - 2*sig*x(2).^4 + (1-aa0-ta+as*ta)*Solar/4;
end
function [x,y] = f5(X,Y) % Dynamical flow equations
k1 = 1/75; % 75 year time constant for the Earth
k2 = 1/25; % 25 year time constant for the Atmosphere
fun = @root2d;
x0 = [0 0];
x = fsolve(fun,x0); % Solve for the temperatures that set the energy fluxes to zero
Ts0 = x(1) + 288; % Surface temperature in Kelvin
Ta0 = x(2) + 288; % Atmosphere temperature in Kelvin
xtmp = -k1*(X - Ts0); % Dynamical equations
ytmp = -k2*(Y - Ta0);
nrm = sqrt(xtmp.^2 + ytmp.^2);
if smallarrow == 1
x = xtmp./nrm;
y = ytmp./nrm;
else
x = xtmp;
y = ytmp;
end
end % end f5
end % end flowatmos
This model has a lot of parameters that can be tweaked. In addition to the parameters in the Table, the time dependence on the blanket properties of the atmosphere are governed by Delta0 and by feedfac for feedback of temperature on the atmosphere, such as increasing cloud cover and decrease ice cover. As an exercise, and using only small changes in the given parameters, find the following cases: 1) An increasing surface temperature is moderated by a falling atmosphere temperature; 2) The Earth goes into thermal run-away and ends like Venus; 3) The Earth initially warms then plummets into an ice age.
At the dawn of quantum theory, Heisenberg, Schrödinger, Bohr and Pauli were embroiled in a dispute over whether trajectories of particles, defined by their positions over time, could exist. The argument against trajectories was based on an apparent paradox: To draw a “line” depicting a trajectory of a particle along a path implies that there is a momentum vector that carries the particle along that path. But a line is a one-dimensional curve through space, and since at any point in time the particle’s position is perfectly localized, then by Heisenberg’s uncertainty principle, it can have no definable momentum to carry it along.
My previous blog shows the way out of this paradox, by assembling wavepackets that are spread in both space and momentum, explicitly obeying the uncertainty principle. This is nothing new to anyone who has taken a quantum course. But the surprising thing is that in some potentials, like a harmonic potential, the wavepacket travels without broadening, just like classical particles on a trajectory. A dramatic demonstration of this can be seen in this YouTube video. But other potentials “break up” the wavepacket, especially potentials that display classical chaos. Because phase space is one of the best tools for studying classical chaos, especially Hamiltonian chaos, it can be enlisted to dig deeper into the question of the quantum trajectory—not just about the existence of a quantum trajectory, but why quantum systems retain a shadow of their classical counterparts.
Phase Space
Phase space is the state space of Hamiltonian systems. Concepts of phase space were first developed by Boltzmann as he worked on the problem of statistical mechanics. Phase space was later codified by Gibbs for statistical mechanics and by Poincare for orbital mechanics, and it was finally given its name by Paul and Tatiana Ehrenfest (a husband-wife team) in correspondence with the German physicist Paul Hertz (See Chapter 6, “The Tangled Tale of Phase Space”, in Galileo Unbound by D. D. Nolte (Oxford, 2018)).
The stretched-out phase-space functions … are very similar to the stochastic layer that forms in separatrix chaos in classical systems.
The idea of phase space is very simple for classical systems: it is just a plot of the momentum of a particle as a function of its position. For a given initial condition, the trajectory of a particle through its natural configuration space (for instance our 3D world) is traced out as a path through phase space. Because there is one momentum variable per degree of freedom, then the dimensionality of phase space for a particle in 3D is 6D, which is difficult to visualize. But for a one-dimensional dynamical system, like a simple harmonic oscillator (SHO) oscillating in a line, the phase space is just two-dimensional, which is easy to see. The phase-space trajectories of an SHO are simply ellipses, and if the momentum axis is scaled appropriately, the trajectories are circles. The particle trajectory in phase space can be animated just like a trajectory through configuration space as the position and momentum change in time p(x(t)). For the SHO, the point follows the path of a circle going clockwise.
Fig. 1 Phase space of the simple harmonic oscillator. The “orbits” have constant energy.
A more interesting phase space is for the simple pendulum, shown in Fig. 2. There are two types of orbits: open and closed. The closed orbits near the origin are like those of a SHO. The open orbits are when the pendulum is spinning around. The dividing line between the open and closed orbits is called a separatrix. Where the separatrix intersects itself is a saddle point. This saddle point is the most important part of the phase space portrait: it is where chaos emerges when perturbations are added.
Fig. 2 Phase space for a simple pendulum. For small amplitudes the orbits are closed like those of a SHO. For large amplitudes the orbits become open as the pendulum spins about its axis. (Reproduced from Introduction to Modern Dynamics, 2nd Ed., pg. )
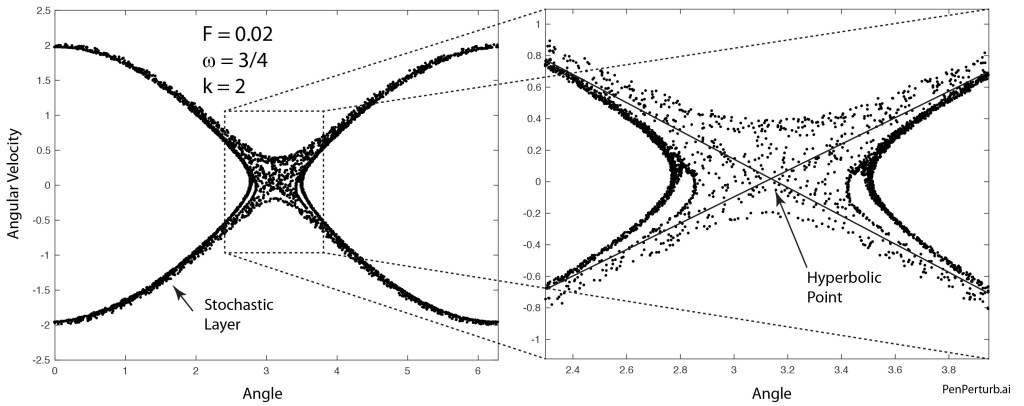
One route to classical chaos is through what is known as “separatrix chaos”. It is easy to see why saddle points (also known as hyperbolic points) are the source of chaos: as the system trajectory approaches the saddle, it has two options of which directions to go. Any additional degree of freedom in the system (like a harmonic drive) can make the system go one way on one approach, and the other way on another approach, mixing up the trajectories. An example of the stochastic layer of separatrix chaos is shown in Fig. 3 for a damped driven pendulum. The chaotic behavior that originates at the saddle point extends out along the entire separatrix.
Fig. 3 The stochastic layer of separatrix chaos for a damped driven pendulum. (Reproduced from Introduction to Modern Dynamics, 2nd Ed., pg. )
The main question about whether or not there is a quantum trajectory depends on how quantum packets behave as they approach a saddle point in phase space. Since packets are spread out, it would be reasonable to assume that parts of the packet will go one way, and parts of the packet will go another. But first, one has to ask: Is a phase-space description of quantum systems even possible?
Quantum Phase Space: The Wigner Distribution Function
Phase-space portraits are arguably the most powerful tool in the toolbox of classical dynamics, and one would like to retain its uses for quantum systems. However, there is that pesky paradox about quantum trajectories that cannot admit the existence of one-dimensional curves through such a phase space. Furthermore, there is no direct way of taking a wavefunction and simply “finding” its position or momentum to plot points on such a quantum phase space.
The answer was found in 1932 by Eugene Wigner (1902 – 1905), an Hungarian physicist working at Princeton. He realized that it was impossible to construct a quantum probability distribution in phase space that had positive values everywhere. This is a problem, because negative probabilities have no direct interpretation. But Wigner showed that if one relaxed the requirements a bit, so that expectation values computed over some distribution function (that had positive and negative values) gave correct answers that matched experiments, then this distribution function would “stand in” for an actual probability distribution.
The distribution function that Wigner found is called the Wigner distribution function. Given a wavefunction ψ(x), the Wigner distribution is defined as
Fig. 4 Wigner distribution function in (x, p) phase space.
The Wigner distribution function is the Fourier transform of the convolution of the wavefunction. The pure position dependence of the wavefunction is converted into a spread-out position-momentum function in phase space. For a Gaussian wavefunction ψ(x) with a finite width in space, the W-function in phase space is a two-dimensional Gaussian with finite widths in both space and momentum. In fact, the Δx-Δp product of the W-function is precisely the uncertainty production of the Heisenberg uncertainty relation.
The question of the quantum trajectory from the phase-space perspective becomes whether a Wigner function behaves like a localized “packet” that evolves in phase space in a way analogous to a classical particle, and whether classical chaos is reflected in the behavior of quantum systems.
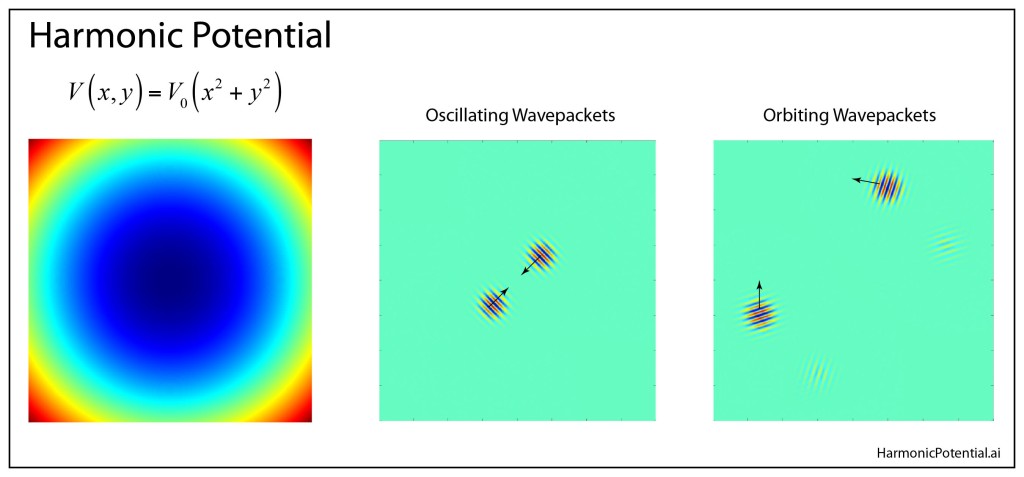
The Harmonic Oscillator
The quantum harmonic oscillator is a rare and special case among quantum potentials, because the energy spacings between all successive states are all the same. This makes it possible for a Gaussian wavefunction, which is a superposition of the eigenstates of the harmonic oscillator, to propagate through the potential without broadening. To see an example of this, watch the first example in this YouTube video for a Schrödinger cat state in a two-dimensional harmonic potential. For this very special potential, the Wigner distribution behaves just like a (broadened) particle on an orbit in phase space, executing nice circular orbits.
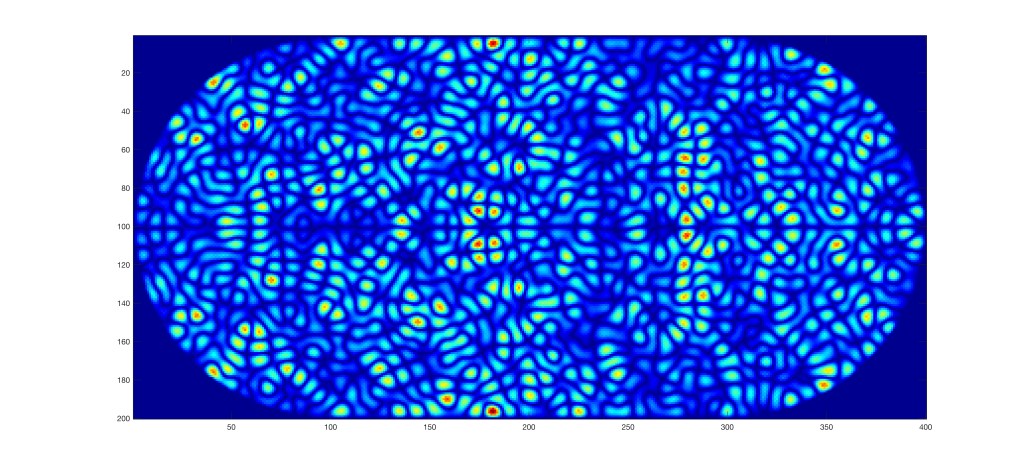
A comparison of the classical phase-space portrait versus the quantum phase-space portrait is shown in Fig. 5. Where the classical particle is a point on an orbit, the quantum particle is spread out, obeying the Δx-Δp Heisenberg product, but following the same orbit as the classical particle.
Fig. 5 Classical versus quantum phase-space portraits for a harmonic oscillator. For a classical particle, the trajectory is a point executing an orbit. For a quantum particle, the trajectory is a Wigner distribution that follows the same orbit as the classical particle.
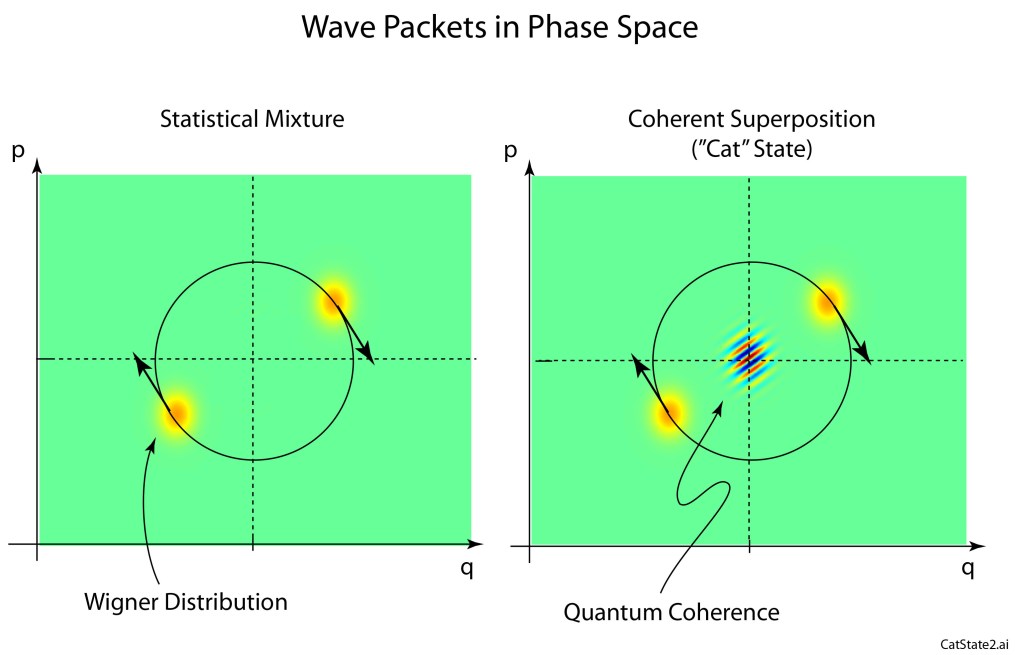
However, a significant new feature appears in the Wigner representation in phase space when there is a coherent superposition of two states, known as a “cat” state, after Schrödinger’s cat. This new feature has no classical analog. It is the coherent interference pattern that appears at the zero-point of the harmonic oscillator for the Schrödinger cat state. There is no such thing as “classical” coherence, so this feature is absent in classical phase space portraits.
Two examples of Wigner distributions are shown in Fig. 6 for a statistical (incoherent) mixture of packets and a coherent superposition of packets. The quantum coherence signature is present in the coherent case but not the statistical mixture case. The coherence in the Wigner distribution represents “off-diagonal” terms in the density matrix that leads to interference effects in quantum systems. Quantum computing algorithms depend critically on such coherences that tend to decay rapidly in real-world physical systems, known as decoherence, and it is possible to make statements about decoherence by watching the zero-point interference.
Fig. 6 Quantum phase-space portraits of double wave packets. On the left, the wave packets have no coherence, being a statistical mixture. On the right is the case for a coherent superposition, or “cat state” for two wave packets in a one-dimensional harmonic oscillator.
Whereas Gaussian wave packets in the quantum harmonic potential behave nearly like classical systems, and their phase-space portraits are almost identical to the classical phase-space view (except for the quantum coherence), most quantum potentials cause wave packets to disperse. And when saddle points are present in the classical case, then we are back to the question about how quantum packets behave as they approach a saddle point in phase space.
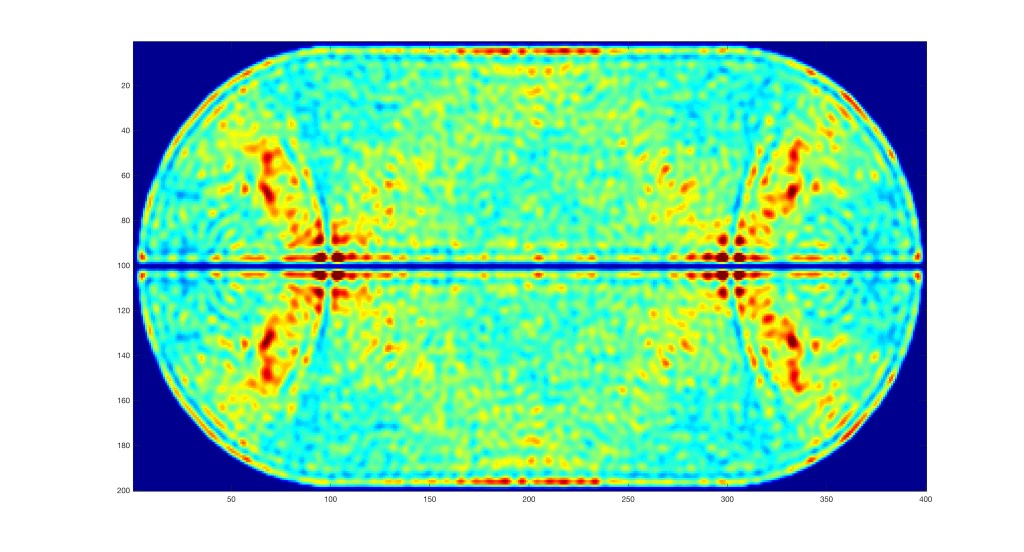
Quantum Pendulum and Separatrix Chaos
One of the simplest anharmonic oscillators is the simple pendulum. In the classical case, the period diverges if the pendulum gets very close to going vertical. A similar thing happens in the quantum case, but because the motion has strong anharmonicity, an initial wave packet tends to spread dramatically as parts of the wavefunction less vertical stretch away from the part of the wave function that is more nearly vertical. Fig. 7 is a snap-shot about a eighth of a period after the wave packet was launched. The packet has already stretched out along the separatrix. A double-cat-state was used, so there is a second packet that has coherent interference with the first. To see a movie of the time evolution of the wave packet and the orbit in quantum phase space, see the YouTube video.
Fig. 7 Wavefunction of a quantum pendulum released near vertical. The phase-space portrait is very similar to the classical case, except that the phase-space distribution is stretched out along the separatrix. The initial state for the phase-space portrait was a cat state.
The simple pendulum does have a saddle point, but it is degenerate because the angle is modulo -2-pi. A simple potential that has a non-degenerate saddle point is a double-well potential.
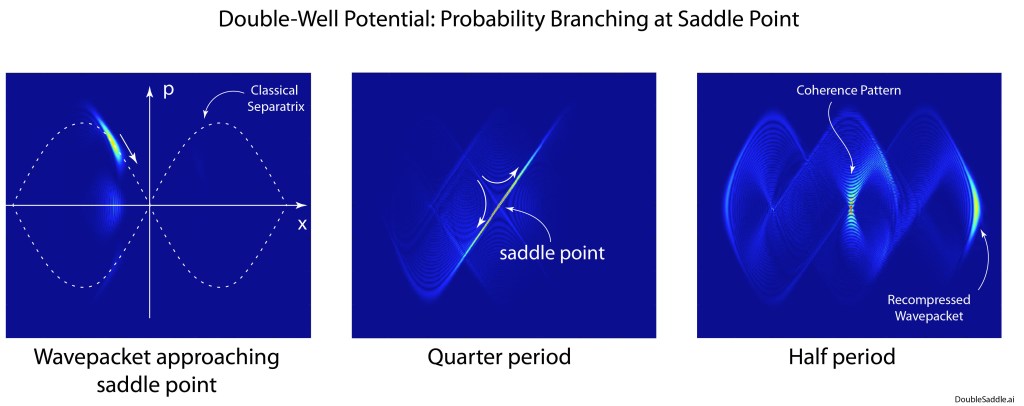
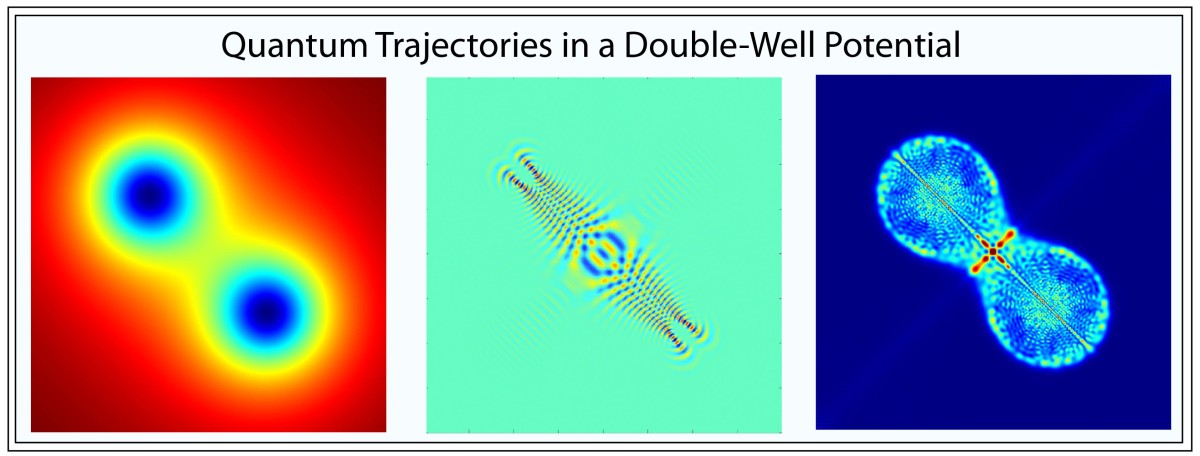
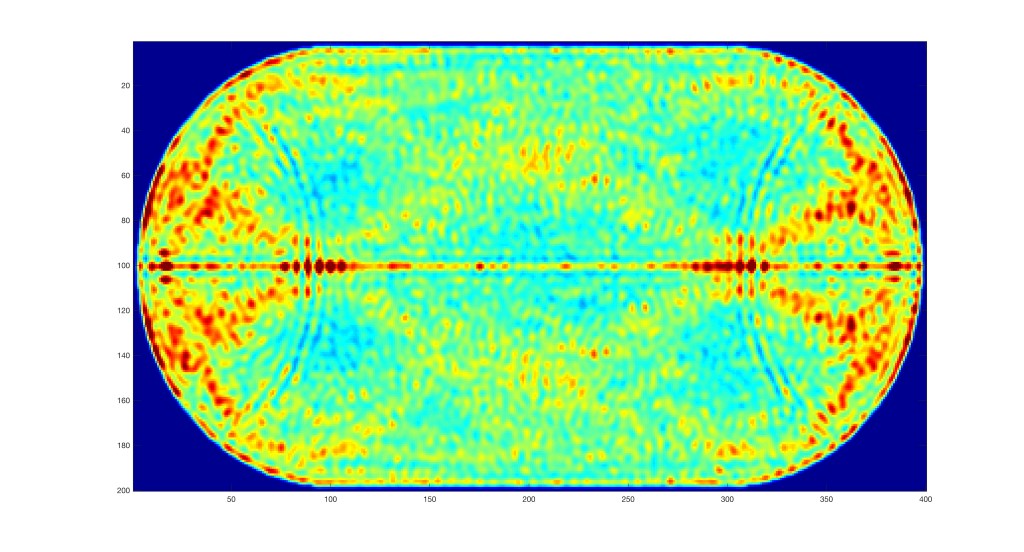
Quantum Double-Well and Separatrix Chaos
The symmetric double-well potential has a saddle point at the mid-point between the two well minima. A wave packet approaching the saddle will split into to packets that will follow the individual separatrixes that emerge from the saddle point (the unstable manifolds). This effect is seen most dramatically in the middle pane of Fig. 8. For the full video of the quantum phase-space evolution, see this YouTube video. The stretched-out distribution in phase space is highly analogous to the separatrix chaos seen for the classical system.
Fig. 8 Phase-space portraits of the Wigner distribution for a wavepacket in a double-well potential. The packet approaches the central saddle point, where the probability density splits along the unstable manifolds.
Conclusion
A common statement often made about quantum chaos is that quantum systems tend to suppress chaos, only exhibiting chaos for special types of orbits that produce quantum scars. However, from the phase-space perspective, the opposite may be true. The stretched-out Wigner distribution functions, for critical wave packets that interact with a saddle point, are very similar to the stochastic layer that forms in separatrix chaos in classical systems. In this sense, the phase-space description brings out the similarity between classical chaos and quantum chaos.
By David D. Nolte Sept. 25, 2022
YouTube Video
For more on the history of quantum trajectories, see Galileo Unbound from Oxford Press:
Heisenberg’s uncertainty principle is a law of physics – it cannot be violated under any circumstances, no matter how much we may want it to yield or how hard we try to bend it. Heisenberg, as he developed his ideas after his lone epiphany like a monk on the isolated island of Helgoland off the north coast of Germany in 1925, became a bit of a zealot, like a religious convert, convinced that all we can say about reality is a measurement outcome. In his view, there was no independent existence of an electron other than what emerged from a measuring apparatus. Reality, to Heisenberg, was just a list of numbers in a spread sheet—matrix elements. He took this line of reasoning so far that he stated without exception that there could be no such thing as a trajectory in a quantum system. When the great battle commenced between Heisenberg’s matrix mechanics against Schrödinger’s wave mechanics, Heisenberg was relentless, denying any reality to Schrödinger’s wavefunction other than as a calculation tool. He was so strident that even Bohr, who was on Heisenberg’s side in the argument, advised Heisenberg to relent [1]. Eventually a compromise was struck, as Heisenberg’s uncertainty principle allowed Schrödinger’s wave functions to exist within limits—his uncertainty limits.
Disaster in the Poconos
Yet the idea of an actual trajectory of a quantum particle remained a type of heresy within the close quantum circles. Years later in 1948, when a young Richard Feynman took the stage at a conference in the Poconos, he almost sabotaged his career in front of Bohr and Dirac—two of the giants who had invented quantum mechanics—by having the audacity to talk about particle trajectories in spacetime diagrams.
Feynman was making his first presentation of a new approach to quantum mechanics that he had developed based on path integrals. The challenge was that his method relied on space-time graphs in which “unphysical” things were allowed to occur. In fact, unphysical things were required to occur, as part of the sum over many histories of his path integrals. For instance, a key element in the approach was allowing electrons to travel backwards in time as positrons, or a process in which the electron and positron annihilate into a single photon, and then the photon decays back into an electron-positron pair—a process that is not allowed by mass and energy conservation. But this is a possible history that must be added to Feynman’s sum.
It all looked like nonsense to the audience, and the talk quickly derailed. Dirac pestered him with questions that he tried to deflect, but Dirac persisted like a raven. A question was raised about the Pauli exclusion principle, about whether an orbital could have three electrons instead of the required two, and Feynman said that it could—all histories were possible and had to be summed over—an answer that dismayed the audience. Finally, as Feynman was drawing another of his space-time graphs showing electrons as lines, Bohr rose to his feet and asked derisively whether Feynman had forgotten Heisenberg’s uncertainty principle that made it impossible to even talk about an electron trajectory.
It was hopeless. The audience gave up and so did Feynman as the talk just fizzled out. It was a disaster. What had been meant to be Feynman’s crowning achievement and his entry to the highest levels of theoretical physics, had been a terrible embarrassment. He slunk home to Cornell where he sank into one of his depressions. At the close of the Pocono conference, Oppenheimer, the reigning king of physics, former head of the successful Manhattan Project and newly selected to head the prestigious Institute for Advanced Study at Princeton, had been thoroughly disappointed by Feynman.
But what Bohr and Dirac and Oppenheimer had failed to understand was that as long as the duration of unphysical processes was shorter than the energy differences involved, then it was literally obeying Heisenberg’s uncertainty principle. Furthermore, Feynman’s trajectories—what became his famous “Feynman Diagrams”—were meant to be merely cartoons—a shorthand way to keep track of lots of different contributions to a scattering process. The quantum processes certainly took place in space and time, conceptually like a trajectory, but only so far as time durations, and energy differences and locations and momentum changes were all within the bounds of the uncertainty principle. Feynman had invented a bold new tool for quantum field theory, able to supply deep results quickly. But no one at the Poconos could see it.
Fig. 1 The first Feynman diagram.
Coherent States
When Feynman had failed so miserably at the Pocono conference, he had taken the stage after Julian Schwinger, who had dazzled everyone with his perfectly scripted presentation of quantum field theory—the competing theory to Feynman’s. Schwinger emerged the clear winner of the contest. At that time, Roy Glauber (1925 – 2018) was a young physicist just taking his PhD from Schwinger at Harvard, and he later received a post-doc position at Princeton’s Institute for Advanced Study where he became part of a miniature revolution in quantum field theory that revolved around—not Schwinger’s difficult mathematics—but Feynman’s diagrammatic method. So Feynman won in the end. Glauber then went on to Caltech, where he filled in for Feynman’s lectures when Feynman was off in Brazil playing the bongos. Glauber eventually returned to Harvard where he was already thinking about the quantum aspects of photons in 1956 when news of the photon correlations in the Hanbury-Brown Twiss (HBT) experiment were published. Three years later, when the laser was invented, he began developing a theory of photon correlations in laser light that he suspected would be fundamentally different than in natural chaotic light.
Because of his background in quantum field theory, and especially quantum electrodynamics, it was fairly easy to couch the quantum optical properties of coherent light in terms of Dirac’s creation and annihilation operators of the electromagnetic field. Glauber developed a “coherent state” operator that was a minimum uncertainty state of the quantized electromagnetic field, related to the minimum-uncertainty wave functions derived initially by Schrödinger in the late 1920’s. The coherent state represents a laser operating well above the lasing threshold and behaved as “the most classical” wavepacket that can be constructed. Glauber was awarded the Nobel Prize in Physics in 2005 for his work on such “Glauber states” in quantum optics.
Fig. 2 Roy Glauber
Quantum Trajectories
Glauber’s coherent states are built up from the natural modes of a harmonic oscillator. Therefore, it should come as no surprise that these coherent-state wavefunctions in a harmonic potential behave just like classical particles with well-defined trajectories. The quadratic potential matches the quadratic argument of the the Gaussian wavepacket, and the pulses propagate within the potential without broadening, as in Fig. 3, showing a snapshot of two wavepackets propagating in a two-dimensional harmonic potential. This is a somewhat radical situation, because most wavepackets in most potentials (or even in free space) broaden as they propagate. The quadratic potential is a special case that is generally not representative of how quantum systems behave.
Fig. 3 Harmonic potential in 2D and two examples of pairs of pulses propagating without broadening. The wavepackets in the center are oscillating in line, and the wavepackets on the right are orbiting the center of the potential in opposite directions. (Movies of the quantum trajectories can be viewed at Physics Unbound.)
To illustrate this special status for the quadratic potential, the wavepackets can be launched in a potential with a quartic perturbation. The quartic potential is anharmonic—the frequency of oscillation depends on the amplitude of oscillation unlike for the harmonic oscillator, where amplitude and frequency are independent. The quartic potential is integrable, like the harmonic oscillator, and there is no avenue for chaos in the classical analog. Nonetheless, wavepackets broaden as they propagate in the quartic potential, eventually spread out into a ring in the configuration space, as in Fig. 4.
Fig. 4 Potential with a quartic corrections. The initial gaussian pulses spread into a “ring” orbiting the center of the potential.
A potential with integrability has as many conserved quantities to the motion as there are degrees of freedom. Because the quartic potential is integrable, the quantum wavefunction may spread, but it remains highly regular, as in the “ring” that eventually forms over time. However, integrable potentials are the exception rather than the rule. Most potentials lead to nonintegrable motion that opens the door to chaos.
A classic (and classical) potential that exhibits chaos in a two-dimensional configuration space is the famous Henon-Heiles potential. This has a four-dimensional phase space which admits classical chaos. The potential has a three-fold symmetry which is one reason it is non-integral, since a particle must “decide” which way to go when it approaches a saddle point. In the quantum regime, wavepackets face the same decision, leading to a breakup of the wavepacket on top of a general broadening. This allows the wavefunction eventually to distribute across the entire configuration space, as in Fig. 5.
Fig. 5 The Henon-Heiles two-dimensional potential supports Hamiltonian chaos in the classical regime. In the quantum regime, the wavefunction spreads to eventually fill the accessible configuration space (for constant energy).
Youtube Video
Movies of quantum trajectories can be viewed at my Youtube Channel, Physics Unbound. The answer to the question “Is there a quantum trajectory?” can be seen visually as the movies run—they do exist in a very clear sense under special conditions, especially coherent states in a harmonic oscillator. And the concept of a quantum trajectory also carries over from a classical trajectory in cases when the classical motion is integrable, even in cases when the wavefunction spreads over time. However, for classical systems that display chaotic motion, wavefunctions that begin as coherent states break up into chaotic wavefunctions that fill the accessible configuration space for a given energy. The character of quantum evolution of coherent states—the most classical of quantum wavefunctions—in these cases reflects the underlying character of chaotic motion in the classical analogs. This process can be seen directly watching the movies as a wavepacket approaches a saddle point in the potential and is split. Successive splits of the multiple wavepackets as they interact with the saddle points is what eventually distributes the full wavefunction into its chaotic form.
Therefore, the idea of a “quantum trajectory”, so thoroughly dismissed by Heisenberg, remains a phenomenological guide that can help give insight into the behavior of quantum systems—both integrable and chaotic.
As a side note, the laws of quantum physics obey time-reversal symmetry just as the classical equations do. In the third movie of “A Quantum Ballet“, wavefunctions in a double-well potential are tracked in time as they start from coherent states that break up into chaotic wavefunctions. It is like watching entropy in action as an ordered state devolves into a disordered state. But at the half-way point of the movie, the imaginary part of the wavefunction has its sign flipped, and the dynamics continue. But now the wavefunctions move from disorder into an ordered state, seemingly going against the second law of thermodynamics. Flipping the sign of the imaginary part of the wavefunction at just one instant in time plays the role of a time-reversal operation, and there is no violation of the second law.
Alice’s disturbing adventures in Wonderland tumbled upon her like a string of accidents as she wandered a world of chaos. Rules were never what they seemed and shifted whenever they wanted. She even met a cat who grinned ear-to-ear and could disappear entirely, or almost entirely, leaving only its grin.
The vanishing Cheshire Cat reminds us of another famous cat—Arnold’s Cat—that introduced the ideas of stretching and folding of phase-space volumes in non-integrable Hamiltonian systems. But when Arnold’s Cat becomes a Quantum Cat, a central question remains: What happens to the chaotic behavior of the classical system … does it survive the transition to quantum mechanics? The answer is surprisingly like the grin of the Cheshire Cat—the cat vanishes, but the grin remains. In the quantum world of the Cheshire Cat, the grin of the classical cat remains even after the rest of the cat vanished.
The Cheshire Cat fades away, leaving only its grin, like a fine filament, as classical chaos fades into quantum, leaving behind a quantum scar.
The Quantum Mechanics of Classically Chaotic Systems
The simplest Hamiltonian systems are integrable—they have as many constants of the motion as degrees of freedom. This holds for quantum systems as well as for classical. There is also a strong correspondence between classical and quantum systems for the integrable cases—literally the Correspondence Principle—that states that quantum systems at high quantum number approach classical behavior. Even at low quantum numbers, classical resonances are mirrored by quantum eigenfrequencies that can show highly regular spectra.
But integrable systems are rare—surprisingly rare. Almost no real-world Hamiltonian system is integrable, because the real world warps the ideal. No spring can displace indefinitely, and no potential is perfectly quadratic. There are always real-world non-idealities that destroy one constant of the motion or another, opening the door to chaos.
When classical Hamiltonian systems become chaotic, they don’t do it suddenly. Almost all transitions to chaos in Hamiltonian systems are gradual. One of the best examples of this is the KAM theory that starts with invariant action integrals that generate invariant tori in phase space. As nonintegrable perturbations increase, the tori break up slowly into island chains of stability as chaos infiltrates the separatrixes—first as thin filaments of chaos surrounding the islands—then growing in width to take up more and more of phase space. Even when chaos is fully developed, small islands of stability can remain—the remnants of stable orbits of the unperturbed system.
When the classical becomes quantum, chaos softens. Quantum wave functions don’t like to be confined—they spread and they tunnel. The separatrix of classical chaos—that barrier between regions of phase space—cannot constrain the exponential tails of wave functions. And the origin of chaos itself—the homoclinic point of the separatrix—gets washed out. Then the regular orbits of the classical system reassert themselves, and they appear, like the vestige of the Cheshire Cat, as a grin.
The Quantum Circus
The empty stadium is a surprisingly rich dynamical system that has unexpected structure in both the classical and the quantum domain. Its importance in classical dynamics comes from the fact that its periodic orbits are unstable and its non-periodic orbits are ergodic (filling all available space if given long enough). The stadium itself is empty so that particles (classical or quantum) are free to propagate between reflections from the perfectly-reflecting walls of the stadium. The ergodicity comes from the fact that the stadium—like a classic Roman chariot-race stadium, also known as a circus—is not a circle, but has a straight stretch between two half circles. This simple modification takes the stable orbits of the circle into the unstable orbits of the stadium.
A single classical orbit in a stadium is shown in Fig 1. This is an ergodic orbit that is non-periodic and eventually would fill the entire stadium space. There are other orbits that are nearly periodic, such as one that bounces back and forth vertically between the linear portions, but even this orbit will eventually wander into the circular part of the stadium and then become ergodic. The big quantum-classical question is what happens to these classical orbits when the stadium is shrunk to the nanoscale?
Fig. 1 A classical trajectory in a stadium. It will eventually visit every point, a property known as ergodicity.
Simulating an evolving quantum wavefunction in free space is surprisingly simple. Given a beginning quantum wavefunction A(x,y,t0), the discrete update equation is
Perfect reflection from the boundaries of the stadium are incorporated through imposing a boundary condition that sends the wavefunction to zero. Simple!
A snap-shot of a wavefunction evolving in the stadium is shown in Fig. 2. To see a movie of the time evolution, see my YouTube episode.
Fig. 2 Snapshot of a quantum wavefunction in the stadium. (From YouTube)
The time average of the wavefunction after a long time has passed is shown in Fig. 3. Other than the horizontal nodal line down the center of the stadium, there is little discernible structure or symmetry. This is also true for the mean squared wavefunction shown in Fig. 4, although there is some structure that may be emerging in the semi-circular regions.
Fig. 3 Time-average wavefunction after a long time.
Fig. 4 Time-average of the squared wavefunction after a long time.
On the other hand, for special initial conditions that have a lot of symmetry, something remarkable happens. Fig. 5 shows several mean-squared results for special initial conditions. There is definite structure in these cases that were given the somewhat ugly name “quantum scars” in the 1980’s by Eric Heller who was one of the first to study this phenomenon [1].
Quantum ScarsQuantum ScarsQuantum Scars
Fig. 5 Quantum scars reflect periodic (but unstable) orbits of the classical system. Quantum effects tend to quench chaos and favor regular motion.
One can superpose highly-symmetric classical trajectories onto the figures, as shown in the bottom row. All of these classical orbits go through a high-symmetry point, such as the center of the stadium (on the left image) and through the focal point of the circular mirrors (in the other two images). The astonishing conclusion of this exercise is that the highly-symmetric periodic classical orbits remain behind as quantum scars—like the Cheshire Cat’s grin—when the system is in the quantum realm. The classical orbits that produce quantum scars have the important property of being periodic but unstable. A slight perturbation from the symmetric trajectory causes it to eventually become ergodic (chaotic). These scars are regions with enhanced probability density, what might be termed “quantum trajectories”, but do not show strong interference patterns.
It is important to make the distinction that it is also possible to construct special wavefunctions that are strictly periodic, such as a wave bouncing perfectly vertically between the straight portions. This leads to large-scale interference patterns that are not the same as the quantum scars.
Quantum Chaos versus Laser Speckle
In addition to the bouncing-wave cases that do not strictly produce quantum scars, there is another “neutral” phenomenon that produces interference patterns that look a lot like scars, but are simply the random addition of lots of plane waves with the same wavelength [2]. A snapshot in time of one of these superpositions is shown in Fig. 6. To see how the waves add together, see the YouTube channel episode.
Fig. 6 The sum of 100 randomly oriented plane waves of constant wavelength. (A snapshot from YouTube.)
By David D. Nolte, Aug. 14, 2022
YouTube Video
Read more about the history of chaos theory in Galileo Unbound from Oxford Press:
Machine learning is characterized, more than by any other aspect, by the high dimensionality of the data spaces it seeks to find patterns in. Hence, one of the principle functions of machine learning is to reduce the dimensionality of the data to lower dimensions—a process known as dimensionality reduction.
There are two driving reasons to reduce the dimensionality of data:
First, typical dimensionalities faced by machine learning problems can be in the hundreds or thousands. Trying to visualize such high dimensions may sound mind expanding, but it is really just saying that a data problem may have hundreds or thousands of different data entries for a single event. And many, or even most, of those entries may not be independent. While many others may be pure noise—or at least not relevant to the pattern. Deep learning dimensionality reduction seeks to find the dependences—many of them nonlinear and non-single-valued (non-invertible)—and to reject the noise channels.
Second, the geometry of high dimension is highly unintuitive. Many of the things we take for granted in our pitifully low dimension of 3 (or 4 if you include time) just don’t hold in high dimensions. For instance, in very high dimensions almost all random vectors in a hyperspace are orthogonal, and almost all random unit vectors in the hyperspace are equidistant. Even the topology of landscapes in high dimensions is unintuitive—there are far more mountain ridges than mountain peaks—with profound consequences for dynamical processes such as random walks (see my Blog on a Random Walk in 10 Dimensions). In fact, we owe our evolutionary existence to this effect! Therefore, deep dimensionality reduction is a way to bring complex data down to a dimensionality where our intuition can be applied to “explain” the data.
But what is a dimension? And can you find the “right” dimensionality when performing dimensionality reduction? Once again, our intuition struggles with these questions, as first discovered by a nineteenth-century German mathematician whose mind-expanding explorations of the essence of different types of infinity shattered the very concept of dimension.
George Cantor
Georg Cantor (1845 – 1918) was born in Russia, and the family moved to Germany while Cantor was still young. In 1863, he enrolled at the University of Berlin where he sat on lectures by Weierstrass and Kronecker. He received his doctorate in 1867 and his Habilitation in 1869, moving into a faculty position at the University of Halle and remaining there for the rest of his career. Cantor published a paper early in 1872 on the question of whether the representation of an arbitrary function by a Fourier series is unique. He had found that even though the series might converge to a function almost everywhere, there surprisingly could still be an infinite number of points where the convergence failed. Originally, Cantor was interested in the behavior of functions at these points, but his interest soon shifted to the properties of the points themselves, which became his life’s work as he developed set theory and transfinite mathematics.
Georg Cantor (1845 – 1918)
In 1878, in a letter to his friend Richard Dedekind, Cantor showed that there was a one-to-one correspondence between the real numbers and the points in any n-dimensional space. He was so surprised by his own result that he wrote to Dedekind “I see it, but I don’t believe it.” Previously, the ideas of a dimension, moving in a succession from one (a line) to two (a plane) to three (a volume) had been absolute. However, with his newly-discovered mapping, the solid concepts of dimension and dimensionality began to dissolve. This was just the beginning of a long history of altered concepts of dimension (see my Blog on the History of Fractals).
Mapping Two Dimensions to One
Cantor devised a simple mapping that is at once obvious and subtle. To take a specific example of mapping a plane to a line, one can consider the two coordinate values (x,y) both with a closed domain on [0,1]. Each can be expressed as a decimal fraction given by
These two values can be mapped to a single value through a simple “ping-pong” between the decimal digits as
If x and y are irrational, then this presents a simple mapping of a pair of numbers (two-dimensional coordinates) to a single number. In this way, the special significance of two dimensions relative to one dimension is lost. In terms of set theory nomenclature, the cardinality of the two-dimensional R2 is the same as for the one-dimensions R.
Nonetheless, intuition about dimension still has it merits, and a subtle aspect of this mapping is that it contains discontinuities. These discontinuities are countably infinite, but they do disrupt any smooth transformation from 2D to 1D, which is where the concepts of intrinsic dimension are hidden. The topological dimension of the plane is clearly equal to 2, and that of the line is clearly equal to 1, determined by the dimensionality D+1 of cuts that are required to separate the sets. The area is separated by a D = 1 line, while the line is separated by a D= 0 point.
Fig. 1 A mapping of a 2D plane to a 1D line. Every point in the plane has an associated point on the line (except for a countably infinite number of special points … see the next figure.)
While the discontinuities help preserve the notions of dimension, and they are countably infinite (with the cardinality of the rational numbers), they pertain merely to the representation of number by decimals. As an example, in decimal notation for a number a = 14159/105, one has two equivalent representations
trailing either infinitely many 0’s or infinitely many 9’s. Despite the fact that these representations point to the same number, when it is used as one of the pairs in the bijection of Fig. 1, it produces two distinctly different numbers of t in R. Fortunately, there is a way to literally sweep this under the rug. Any time one retrieves a number that has repeating 0’s or 9’s, simply sweep it to the right it by dividing by a power of 10 to a region of trailing zeros for a different number, call it b, as in Fig. 2. The shifted version of a will not overlap with the number b, because b also ends in repeating 0’s or 9’s and so is swept farther to the right, and so on to infinity, so none of these numbers overlap, each is distinct, and the mapping becomes what is known as a bijection with one-to-one correspondence.
Fig. 3 The “measure-zero” fix. Numbers that have two equivalent representations can be shifted to the right to replace other numbers that are shifted further to the right, and so on to infinity. There is infinite room within the reals to accommodate the countably infinite number of repeating-decimal numbers.
Space-Filling Curves
When the peripatetic mathematician Guiseppe Peano learned of Cantor’s result for the mapping of 2D to 1D, he sought to demonstrate the correspondence geometrically, and he constructed a continuous curve that filled space, publishing the method in Sur une courbe, qui remplit toute une aire plane [1] in 1890. The construction of Peano’s curve proceeds by taking a square and dividing it into 9 equal sub squares. Lines connect the centers of each of the sub squares. Then each sub square is divided again into 9 sub squares whose centers are all connected by lines. At this stage, the original pattern, repeated 9 times, is connected together by 8 links, forming a single curve. This process is repeated infinitely many times, resulting in a curve that passes through every point of the original plane square. In this way, a line is made to fill a plane. Where Cantor had proven abstractly that the cardinality of the real numbers was the same as the points in n-dimensional space, Peano created a specific example.
This was followed quickly by another construction, invented by David Hilbert in 1891, that divided the square into four instead of nine, simplifying the construction, but also showing that such constructions were easily generated [2]. The space-filling curves of Peano and Hilbert have the extreme properties that a one-dimensional curve approaches every point in a two-dimensional space. These curves have topological dimensionality of 1D and a fractal dimensionality of 2D.
Fig. 3 Peano’s (1890) and Hilbert’s (1891) plane-filling curves. When the iterations are taken to infinity, the curves approach every point of two-dimensional space arbitrarily closely, giving them a dimension D = 2.
A One-Dimensional Deep Discrete Encoder for MNIST
When performing dimensionality reduction in deep learning it is tempting to think that there is an underlying geometry to the data—as if they reside on some submanifold of the original high-dimensional space. While this can be the case (for which dimensionality reduction is called deep metric learning) more often there is no such submanifold. For instance, when there is a highly conditional nature to the different data channels, in which some measurements are conditional on the values of other measurements, then there is no simple contiguous space that supports the data.
It is also tempting to think that a deep learning problem has some intrinsic number of degrees of freedom which should be matched by the selected latent dimensionality for the dimensionality reduction. For instance, if there are roughly five degrees of freedom buried within a complicated data set, then it is tempting to believe that the appropriate latent dimensionality also should be chosen to be five. But this also is missing the mark.
Take, for example, the famous MNIST data set of hand-written digits from 0 to 9. Each digit example is contained in a 28-by28 two-dimensional array that is typically flattened to a 784-element linear vector that locates that single digit example within a 784-dimensional space. The goal is to reduce the dimensionality down to a manageable number—but what should the resulting latent dimensionality be? How many degrees of freedom are involved in writing digits? Furthermore, given that there are ten classes of digits, should the chosen dimensionality of the latent space be related to the number of classes?
Fig. 4 A sampling of MNIST digits.
To illustrate that the dimensionality of the latent space has little to do with degrees of freedom or the number of classes, let’s build a simple discrete encoder that encodes the MNIST data set to the one-dimensional line—following Cantor.
The deep network of the encoder can have a simple structure that terminates with a single neuron that has a piece-wise linear output. The objective function (or loss function) measures the squared distances of the outputs of the single neuron, after transformation by the network, to the associated values 0 to 9. And that is it! Train the network by minimizing the loss function.
Fig. 5 A deep encoder that encodes discrete classes to a one-dimensional latent variable.
The results of the linear encoder are shown in Fig. 6 (the transverse directions are only for ease of visualization…the classification is along the long axis). The different dots are specific digits, and the colors are the digit value. There is a clear trend from 1 through 10, although with this linear encoder there is substantial overlap among the point clouds.
Fig. 6 Latent space for a one-dimensional (line) encoder. The transverse dimensions are only for visualization.
Despite appearances, this one-dimensional discrete line encoder is NOT a form of regression. There is no such thing as 1.5 as the average of a 1-digit and a 2-digit. And 5 is not the average of a 4-digit and a 6-digit. The digits are images that have no intrinsic numerical value. Therefore, this one-dimensional encoder is highly discontinuous, and intuitive ideas about intrinsic dimension for continuous data remain secure.
Summary
The purpose of this Blog (apart from introducing Cantor and his ideas on dimension theory) was to highlight a key question of dimensionality reduction in representation theory: What is the intrinsic dimensionality of a dataset? The answer, in the case of discrete classes, is that there is no intrinsic dimensionality. Having 1 degree of freedom or 10 degrees of freedom, i.e. latent dimensionalities of 1 or 10, is mostly irrelevant. In ideal cases, one is just as good as the other.
On the other hand, for real-world data with its inevitable variability and finite variance, there can be reasons to choose one latent dimensionality over another. In fact, the “best” choice of dimensionality is one less than the number of classes. For instance, in the case of MNIST with its 10 classes, that is a 9-dimensional latent space. The reason this is “best” has to do with the geometry of high-dimensional simplexes, which will be the topic of a future Blog.
By David D. Nolte, June 20, 2022
[1] G.Peano: Sur une courbe, qui remplit toute une aire plane. Mathematische Annalen 36 (1890), 157–160.
[2] D. Hilbert, “Uber die stetige Abbildung einer Linie auf ein Fllichenstilck,” Mathemutische Anna/en, vol. 38, pp. 459-460, (1891)
An old joke goes that Democracy is a terrible form of government … except it’s better than all the others!
Our world today is faced with conflict between democracy and dictatorship. On the one side is the free world, where leaders are chosen by some form of representation of large numbers of citizens and sometimes even a majority. On the other side is authoritarianism where a select few are selected by a select few to govern everyone else.
[I]t has been said that democracy is the worst form of Government except all those other forms that have been tried from time to time; but there is the broad feeling in our country that the people should rule, and that public opinion expressed by all constitutional means, should shape, guide, and control the actions of Ministers who are their servants and not their masters.
Winston Churchill (1947)
An argument in favor of democracy is freedom of choice for the largest segment of the population, plus the ability to remove leaders who fail to provide for the perceived welfare of the most citizens. This makes democracy adaptive, shifting with the times. It also makes leaders accountable for their actions and crimes. An argument in favor of authoritarianism is the myth of the benevolent dictator–someone who knows what’s best for the people even if the people don’t know it themselves.
But dictators are rarely benevolent, and as they become saturated with power, they are corrupted. The criminal massacres, perpetrated by Putin, of Ukrainian civilians is one of the strongest recent arguments against authoritarianism. A single man decides, on a whim, the life and death of thousands or maybe more. The invasion of Ukraine is so egregious and unwarranted, that we wonder how the Russian people can put up with their isolated and manic leader. Yet by some measure more than 60% of the people in Russia approve of the war.
How can the free world see the invasion as the atrocity it is, while Russia’s majority sees it as a just war? The answer is a surprising result of population dynamics known as the replicator-mutator equation. The challenge for us here in the free world is to learn how to game the replicator-mutator equation to break up the monopoly of popular opinion and make Putin pay for his arrogance. This blog explains how “mass hysteria” can arise from forces within a complex environment, and how to construct a possible antidote.
Replicator-Mutator Equation
There are several simple models of population dynamics that try to explain the rise and fall of the number of individuals that belong to varying cohorts within the population. These models incorporate aspects of relative benefit of one group over another, plus the chance to change sides–defection. The dynamics under these conditions can be highly nonlinear and highly non-intuitive. One of the simplest of these models is known as the replicator-mutator model where replication follows the fitness of the cohort, and where individuals can defect to a “more fit” cohort.
The basic dynamics of the model are
where xa is the fraction of the population that is in cohort a, Wab is a transition probability, and φ is the average fitness of the full population. The transition matrix is given by
where fb is the fitness of cohort b and Qba is a stochastic matrix that allows for defection of an individual from one cohort to another. The fitness of a cohort is given by
where pbc is the pay-off matrix for the relative benefit of one cohort at the expense of another. Finally the average fitness is
The Einstein implicit summation convention is assumed in all of these equations, and the metric space in which the dynamics are embedded is “flat” so that there is no essential difference between superscripts and subscripts. There is also a conservation law that the sum over all population fractions equals unity.
In the language of population dynamics, this model has frequency-dependent fitness, with defection and pay-off, in a zero-sum game.
One of the simplest questions to answer with this model is how so many people can come to believe one thing. This is known as “opinion uniformity”.
Uniformity versus Diversity
This replicator-mutator model explains the property of opinion uniformity, as well as the opposite extreme of opinion diversity. The starting point for both is the pay-off matrix pbc which is assumed to be unity on the diagonal for b = c and to a constant factor a for b ~= c. This pay-off is symmetric so that all opinions are equally “believable”. The stochastic defection matrix is close to unity on the diagonal, and has random terms on the off-diagonal that are proportional to a constant ε. The defection matrix allows a person from one cohort to defect to the belief system of another cohort if they believe that the new cohort has more merit. Cohorts with greater merit (fitness) gain more members over time, while cohorts with lower merit have fewer members over time.
Note that the fitness increases with the number of members in the cohort. This is the bandwagon effect. A belief system is perceived to have more merit if there are more people who believe it. This clearly creates a positive feedback that would cause this cohort to grow. Even though all the cohorts have this same positive feedback, the zero-sum rule only allows one of the cohorts to grow to its maximum extent, taking members away from all the other cohorts. This is illustrated in Fig. 1. One belief system wins, taking almost the full population with it.
Fig. 1 Population fractions evolving as a function of time for a = 0.5 and a small defection rate ε = 0.02. One winner takes almost all the population. These are two views of the same data on semilog and log-log.
What allows the winner to take all is the positive feedback where the fitness of the cohort increases with the number of members, combined with the ability for that cohort to take members from other cohorts through the defection matrix.
However, all of the cohorts are trying the same thing, and the pay-off matrix is fully symmetric and equal for all cohorts, so no cohort is intrinsically “better” than another. This property opens the door to a strong alternative to opinion uniformity. In fact, as more members are allowed to defect, it creates a trend counter to winner-take-all, helping to equalize the cohorts. Suddenly, a bifurcation is passed when the winner-take-all converts discontinuously to a super-symmetric situation when all opinions are held by equal numbers of people. This is illustrated in Fig. 2 for a slightly higher defection rate ε = 0.03. The parameters are identical to those in Fig. 1, but the higher defection rate stabilizes the super-symmetric state of maximum diversity.
Fig. 2 Population fractions for higher defection rate of 0.03. In super-symmetric state, all opinions are held at the same rate with maximum diversity.
These two extreme results of the replicator-mutator equation, that switch suddenly from one to the other dependent on the defection rate, may seem to produce solutions neither of which are ideal for a healthy democracy. One the one hand, in the uniform case where the wining opinion is monolithic, everyone is a carbon-copy of everyone else, which is a form of cultural death (lack of diversity). But, on the other hand, one might argue that maximum opinion diversity is just as concerning, because no-one can agree on anything. If all opinions are equivalent, then everyone in the society believes something different and there is no common ground. But in the diversity case, at least there is no state-level control of the population. In the case of opinion uniformity, the wining opinion can be manipulated by propaganda.
The Propaganda Machine
A government can “seed” the belief networks with propaganda that favors the fitness of what they want their citizens to hear. Because of the positive feedback, any slight advantage of one opinion over others can allow that opinion to gain large numbers through the bandwagon effect. Of course, even stronger control that stifles dissent, for instance by shutting down the free press, makes it that much more likely that the state-controlled story is believed. This may be one reason for the 60% (as of the writing of this blog) support Putin’s war, despite the obvious lies that are being told. This is illustrated in Fig. 3 by boosting the payoff between two similar lies that the government wants its people to believe. These rise to take about 60% of the population. Members of the cohort are brain-washed, not by the government alone, but by all their neighbors who are parroting the same thing.
Fig. 3 Government propaganda acts as a “seed” that makes the propaganda grow faster than other beliefs, even for a defection rate of 0.03 which is above the threshold of Fig. 2.
Breaking the Monopoly of Thought
How do we fight back? Not just against the Kremlin’s propaganda, but also against QANON and Trump’s Big Lie and the pernicious fallacy of nationalism? The answer is simple: diversity of thought! The sliver bullet in the replicator-mutator model is the defection matrix. The existence of a bifurcation means that a relatively small increase in the amount of diverse opinion, and the freedom to swap opinions, can lead to a major qualitative collapse of the monolithic thought, even when supported by government propaganda, as shown in Fig. 4. More people may still believe in the state-supported propaganda than the others, but it is no longer a majority.
Fig. 4 Increasing the defection rate can help equalize free opinions against the state-supported propaganda
The above models were all very homogeneous. It is more realistic that people are connected through small-world networks. In this case, there is much more diversity, as shown in Fig. 5, although the defection rate needs to be much higher to prevent a monolithic opinion from dominating. The state-supported propaganda is buried in the resulting mix of diverse ideas. Therefore, to counteract state control, people must feel free to hop about in their choice of beliefs and have access to other beliefs.
Fig. 5 The defection matrix is multiplied by the adjacency matrix of a small-world network. There is significant diversity of thought, but a relatively high defection rate is needed. The state-supported propaganda is buried in this mix.
This is a bit paradoxical. On the one hand, the connectivity of the internet has fostered the rise of conspiracy theories and other odd-ball ideas. But sustained access to multiple sources of information is the best defense against all that crazy stuff winning out. In other words, not only do we have to put up with the lunatic fringe if we are to have full diversity of thought, but we need to encourage everyone to feel free to “shop around” for different ideas, even if some of them are crazy. Our free society shouldn’t be cancelling people who have divergent opinions, because that sets us down the path to authoritarianism. As a recent add said in the New York Times, “Cancel culture cancels culture.” Unfortunately, authoritarianism is on the rise around the world, and the US almost suffered that fate on Jan. 6, 2021. Furthermore, with Xi aligning with Putin and giving him the green light on Ukraine–cynically on the eve of the Olympic Games (of peace)–the new world order will revolve around that axis for decades to come, if the world survives that long. Diversity and freedom may be the only antidote.
By David D. Nolte, March 24, 2022
Matlab Program: Repmut.m
function repmut
% https://github.itap.purdue.edu/nolte/Matlab-Programs-for-Nonlinear-Dynamics
clear
format compact
N = 63;
p = 0.5;
mutype = 1; % 0 = Hamming 1 = rand
pay = 1; % 0 = Hamming 1 = 1/sqrt(N)
ep = 0.5; % average mutation rate: 0.1 to 0.01 typical (0.4835)
%%%%% Set original population
x0temp = rand(1,N); % Initial population
sx = sum(x0temp);
y0 = x0temp/sx;
Pop0 = sum(y0);
%%%%% Set Adjacency
%node = makeglobal(N);
%node = makeER(N,0.25); % 0.5 0.25
%node = makeSF(N,6); % 12 6
node = makeSW(N,7,0.125); % 15,0.5 7,0.5
[Adj,degree,Lap] = adjacency(node);
%%%%%% Set Hamming distance
for yloop = 1:N
for xloop = 1:N
H(yloop,xloop) = hamming(yloop-1,xloop-1);
end
end
%%%%%%% Set Mutation matrix
if mutype == 0
Qtemp = 1./(1+H/ep); %Mutation matrix on Hamming
Qsum = sum(Qtemp,2);
mnQsum = mean(Qsum);
% Normalize mutation among species
for yloop = 1:N
for xloop = 1:N
Q(yloop,xloop) = Qtemp(yloop,xloop)/Qsum(xloop);
end
end
elseif mutype == 1
S = stochasticmatrix(N);
Stemp = S - diag(diag(S));
Qtemp = ep*Stemp;
sm = sum(Qtemp,2)';
Q = Qtemp + diag(ones(1,N) - sm);
end
figure(1)
imagesc(Q)
title('Mutation Matrix')
colormap(jet)
%%%%%%% Set payoff matrix
if pay == 1
payoff = zeros(N,N);
for yloop = 1:N
payoff(yloop,yloop) = 1;
for xloop = yloop + 1:N
payoff(yloop,xloop) = p;
payoff(xloop,yloop) = p;
payoff(1,N) = 1; % Propaganda
payoff(N,1) = 1;
end
end
elseif pay == 0
payoff = zerodiag(exp(-1*H));
end
figure(2)
imagesc(payoff)
title('Payoff Matrix')
colormap(jet)
% Run time evolution
tspan = [0 4000];
[t,x] = ode45(@quasispec,tspan,y0);
Pop0
[sz,dum] = size(t);
Popend = sum(x(sz,:))
for loop = 1:N
fit(loop) = sum(payoff(:,loop)'.*x(sz,:));
end
phistar = sum(fit.*x(sz,:)) % final average fitness
xend = x(sz,:)
sortxend = sort(xend,'descend');
coher = sum(sortxend(1:2))
figure(3)
clf
h = colormap(lines);
for loop = 1:N
plot(t,x(:,loop),'Color',h(round(loop*64/N),:),'LineWidth',1.25)
hold on
end
hold off
figure(4)
clf
for loop = 1:N
semilogx(t,x(:,loop),'Color',h(round(loop*64/N),:),'LineWidth',1.25)
hold on
end
hold off
figure(5)
clf
for loop = 1:N
semilogy(t,x(:,loop),'Color',h(round(loop*64/N),:),'LineWidth',1.25)
hold on
end
hold off
figure(6)
clf
for loop = 1:N
loglog(t,x(:,loop),'Color',h(round(loop*64/N),:),'LineWidth',1.25)
hold on
end
hold off
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function yd = quasispec(~,y)
for floop = 1:N
f(floop) = sum(payoff(:,floop).*y);
end
Connect = Adj + eye(N);
% Transition matrix
for yyloop = 1:N
for xxloop = 1:N
W(yyloop,xxloop) = f(yyloop)*(Connect(yyloop,xxloop)*Q(yyloop,xxloop));
end
end
phi = sum(f'.*y); % Average fitness of population
yd = W*y - phi*y;
end % end quasispec
end
Further Reading
M. A. Nowak, Evolutionary Dynamics: Exploring the Equations of Life. Cambridge, Mass.: Harvard University Press, 2006.
There are many known super-Jupiters that orbit their stars—they are detected through a slight Doppler wobble they induce on their stars [1]. But what would become of a rocky planet also orbiting those stars as they feel the tug of both the star and the super planet?
This is not of immediate concern for us, because our solar system has had its current configuration of planets for over 4 billion years. But there can be wandering interstellar planets or brown dwarfs that could visit our solar system, like Oumuamua did in 2017, but much bigger and able to scramble the planetary orbits. Such hypothesized astronomical objects have been given the name “Nemesis“, and it warrants thought on what living in an altered solar system might be like.
What would happen to Earth if Jupiter were 50 times bigger? Could we survive?
The Three-Body Problem
The Sun-Earth-Jupiter configuration is a three-body problem that has a long and interesting history, playing a key role in several aspects of modern dynamics [2]. There is no general analytical solution to the three-body problem. To find the behavior of three mutually interacting bodies requires numerical solution. However, there are subsets of the three-body problem that do yield to partial analytical approaches. One of these is called the restricted three-body problem [3]. It consists of two massive bodies plus a third (nearly) massless body that all move in a plane. This restricted problem was first tackled by Euler and later by Poincaré, who discovered the existence of chaos in its solutions.
The geometry of the restricted three-body problem is shown in Fig. 1. In this problem, take mass m1 = mS to be the Sun’s mass, m2 = mJ to be Jupiter’s mass, and the third (small) mass is the Earth.
Fig. 1 The restricted 3-body problem in the plane. The third mass is negligible relative to the first two masses that obey 2-body dynamics.
The equation of motion for the Earth is
where
and the parameter ξ characterizes the strength of the perturbation of the Earth’s orbit around the Sun. The parameters for the Jupiter-Sun system are
with
for the 11.86 year journey of Jupiter around the Sun. Eq. (1) is a four-dimensional non-autonomous flow
The solutions of an Earth orbit are shown in Fig.2. The natural Earth-Sun-Jupiter system has a mass ratio mJ/mS = 0.001 for Jupiter relative to the Sun mass. Even in this case, Jupiter causes perturbations of the Earth’s orbit by about one percent. If the mass of Jupiter increases, the perturbations would grow larger until around ξ= 0.06 when the perturbations become severe and the orbit grows unstable. The Earth gains energy from the momentum of the Sun-Jupiter system and can reach escape velocity. The simulation for a mass ratio of 0.07 shows the Earth ejected from the Solar System.
Fig.2 Orbit of Earth as a function of the size of a Jupiter-like planet. The natural system has a Jupiter-Earth mass ratio of 0.03. As the size of Jupiter increases, the Earth orbit becomes unstable and can acquire escape velocity to escape from the Solar System. From body3.m. (Reprinted from Ref. [4])
The chances for ejection depends on initial conditions for these simulations, but generally the danger becomes severe when Jupiter is about 50 times larger than it currently is. Otherwise the Earth remains safe from ejection. However, if the Earth is to keep its climate intact, then Jupiter should not be any larger than about 5 times its current size. At the other extreme, for a planet 70 times larger than Jupiter, the Earth may not get ejected at once, but it can take a wild ride through the solar system. A simulation for a 70x Jupiter is shown in Fig. 3. In this case, the Earth is captured for a while as a “moon” of Jupiter in a very tight orbit around the super planet as it orbits the sun before it is set free again to orbit the sun in highly elliptical orbits. Because of the premise of the restricted three-body problem, the Earth has no effect on the orbit of Jupiter.
Fig. 3 Orbit of Earth for TJ = 11.86 years and ξ = 0.069. The radius of Jupiter is RJ = 5.2. Earth is “captured” for a while by Jupiter into a very tight orbit.
Resonance
If Nemesis were to swing by and scramble the solar system, then Jupiter might move closer to the Earth. More ominously, the period of Jupiter’s orbit could come into resonance with the Earth’s period. This occurs when the ratio of orbital periods is a ratio of small integers. Resonance can amplify small perturbations, so perhaps Jupiter would become a danger to Earth. However, the forces exerted by Jupiter on the Earth changes the Earth’s orbit and hence its period, preventing strict resonance to occur, and the Earth is not ejected from the solar system even for initial rational periods or larger planet mass. This is related to the famous KAM theory of resonances by Kolmogorov, Arnold and Moser that tends to protect the Earth from the chaos of the solar system. More often than not in these scenarios, the Earth is either captured by the super Jupiter, or it is thrown into a large orbit that is still bound to the sun. Some examples are given in the following figures.
Fig. 4 Orbit of Earth for an initial 8:1 resonance of TJ = 8 years and ξ = 0.073. The Radius of Jupiter is R = 4. Jupiter perturbs the Earth’s orbit so strongly that the 8:1 resonance is quickly removed.
Fig. 5 Earth orbit for TJ = 12 years and ξ = 0.071. The Earth is thrown into a nearly circular orbit beyond the orbit of Saturn.
Fig. 6 Earth Orbit for TJ = 4 years and ξ = 0.0615. Earth is thrown into an orbit of high ellipticity out to the orbit of Neptune.
Life on a planet in a solar system with two large bodies has been envisioned in dramatic detail in the science fiction novel “Three-Body Problem” by Liu Cixin about the Trisolarians of the closest known exoplanet to Earth–Proxima Centauri b.
This Blog Post is a Companion to the undergraduate physics textbook Modern Dynamics: Chaos, Networks, Space and Time, 2nd ed. (Oxford, 2019) introducing Lagrangians and Hamiltonians, chaos theory, complex systems, synchronization, neural networks, econophysics and Special and General Relativity.