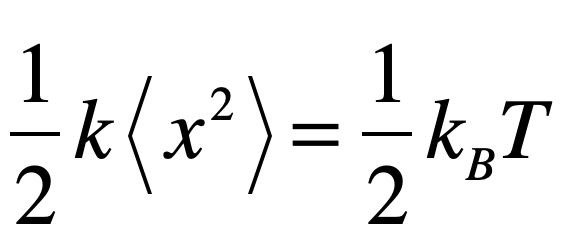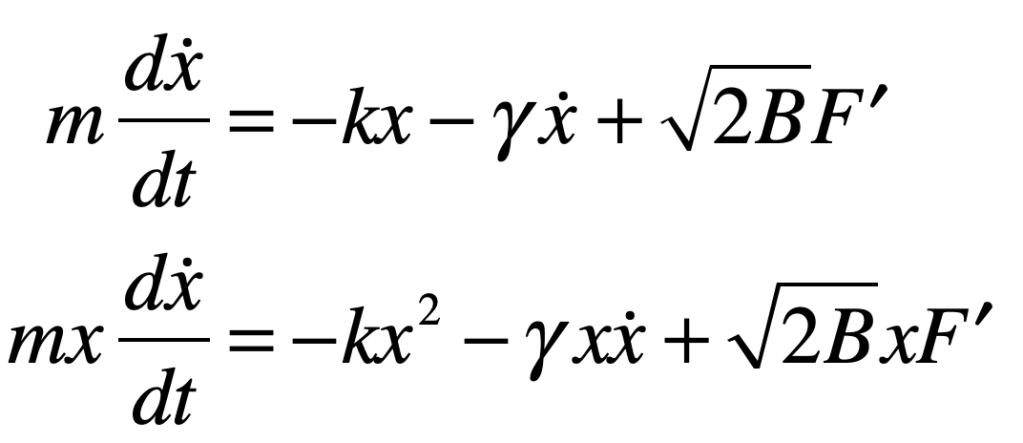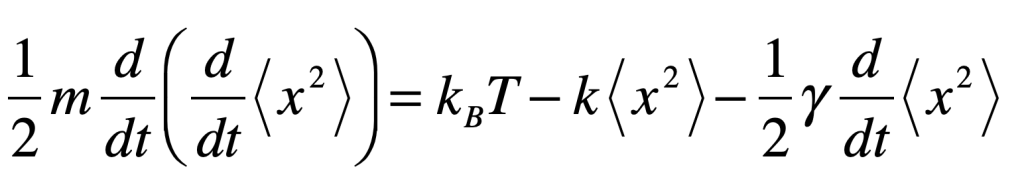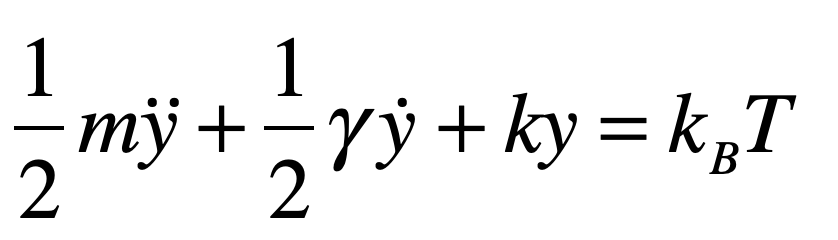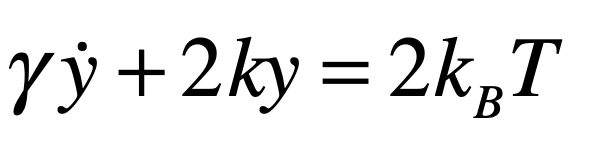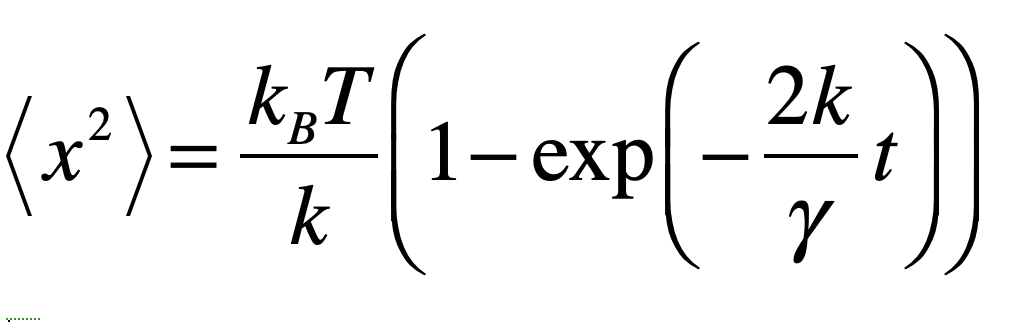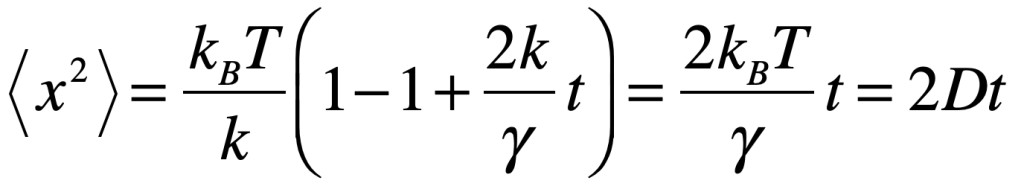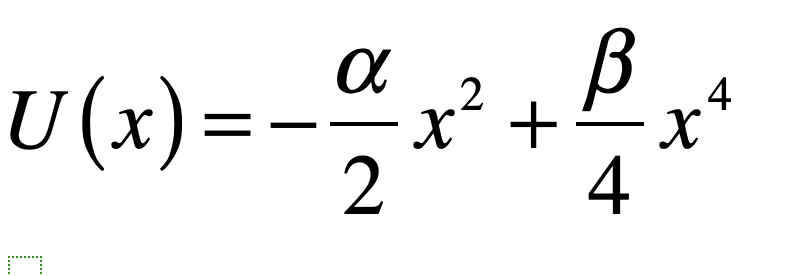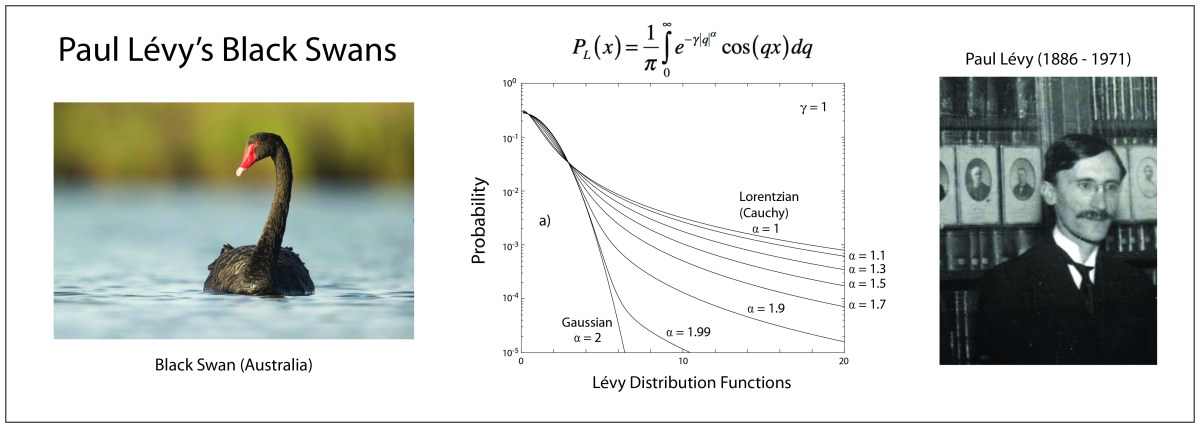
The Black Swan was a mythical beast invented by the Roman poet Juvenal as a metaphor for things that are so rare they can only be imagined. His quote goes “rara avis in terris nigroque simillima cygno” (a rare bird in the lands and very much like a black swan).
Imagine the shock, then, when the Dutch explorer Willem de Vlamingh first saw black swans in Australia in 1697. The metaphor morphed into a new use, meaning when a broadly held belief (the impossibility of black swans) is refuted by a single new observation.
For instance, in 1870 the biologist Thomas Henry Huxley, known as “Darwin’s Bulldog” for his avid defense of Darwin’s theories, delivered a speech in Liverpool, England, where he was quoted in Nature magazine as saying,
… the great tragedy of Science—the slaying of a beautiful hypothesis by an ugly fact
This quote has been picked up and repeated over the years in many different contexts.
One of those contexts applies to the fate of a beautiful economic theory, proposed by Fischer Black and Myron Scholes in 1973, as a way to make the perfect hedge on Wall Street, purportedly risk free, yet guaranteeing a positive return in spite of the ups-and-downs of stock prices. Scholes and Black launched an investment company in 1994 to cash in on this beautiful theory, returning an unbelievable 40% on investment. Black died in 1995, but Scholes was awarded the Nobel Prize in Economics in 1997. The next year, the fund went out of business. The ugly fact that flew in the face of Black-Scholes was the Black Swan.
The Black Swan
A Black Swan is an outlier measurement that occurs in a sequence of data points. Up until the Black Swan event, the data points behave normally, following the usual statistics we have all come to expect, maybe a Gaussian distribution or some other form of exponential that dominate most variable phenomena.

But then a Black Swan occurs. It has a value so unexpected, and so unlike all the other measurements, that it is often assumed to be wrong and possibly even thrown out because it screws up the otherwise nice statistics. That single data point skews averages and standard deviations in non-negligible ways. The response to such a disturbing event is to take even more data to let the averages settle down again … until another Black Swan hits and again skews the mean value. However, such outliers are often not spurious measurements but are actually a natural part of the process. They should not, and can not, be thrown out without compromising the statistical integrity of the study.
This outlier phenomenon came to mainstream attention when the author Nassim Nicholas Taleb, in his influential 2007 book, The Black Swan: The Impact of the Highly Improbable, pointed out that it was a central part of virtually every aspect of modern life, whether in business, or the development of new technologies, or the running of elections, or the behavior of financial markets. Things that seemed to be well behaved … a set of products, or a collective society, or a series of governmental policies … are suddenly disrupted by a new invention, or a new law, or a bad Supreme Court decision, or a war, or a stock-market crash.
As an illustration, let’s see where Black-Scholes went wrong.
The Perfect Hedge on Wall Street?
Fischer Black (1938 – 1995) was a PhD advisor’s nightmare. He had graduated as an undergraduate physics major from Harvard in 1959, but then switched to mathematics for graduate school, then switched to computers, then switched again to artificial intelligence, after which he was thrown out of the graduate program at Harvard for having a serious lack of focus. So he joined the RAND corporation, where he had time to play with his ideas, eventually approaching Marvin Minsky at MIT, who helped guide him to an acceptable thesis that he was allowed to submit to the Harvard program for his PhD in applied mathematics. After that, he went to work in financial markets.
His famous contribution to financial theory was the Black-Scholes paper of 1973 on “The Pricing of Options and Corporate Liabilities” co-authored with Byron Scholes. Hedging is a venerable tradition on Wall Street. To hedge means that a broker sells an option (to purchase a stock at a given price at a later time) assuming that the stock will fall in value (selling short), and then buys, as insurance against the price rising, a number of shares of the same asset (buying long). If the broker balances enough long shares with enough short options, then the portfolio’s value is insulated from the day-to-day fluctuations of the value of the underlying asset.
This type of portfolio is one example of a financial instrument called a derivative. The name comes from the fact that the value of the portfolio is derived from the values of the underlying assets. The challenge with derivatives is finding their “true” value at any time before they mature. If a broker knew the “true” value of a derivative, then there would be no risk in buying and selling derivatives.
To be risk free, the value of the derivative needs to be independent of the fluctuations. This appears at first to be a difficult problem, because fluctuations are random and cannot be predicted. But the solution actually relies on just this condition of randomness. If the random fluctuations in stock prices are equivalent to a random walk superposed on the average rate of return, then perfect hedges can be constructed with impunity.
To make a hedge on an underlying asset, create a portfolio by selling one call option (selling short) and buying a number N shares of the asset (buying long) as insurance against the possibility that the asset value will rise. The value of this portfolio is

If the number N is chosen correctly, then the short and long positions will balance, and the portfolio will be protected from fluctuations in the underlying asset price. To find N, consider the change in the value of the portfolio as the variables fluctuate
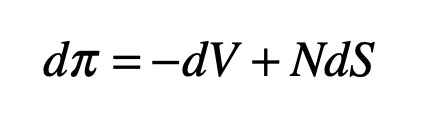
and use an elegant result known as Ito’s Formula (a stochastic differential equation that includes the effects of a stochastic variable) to yield
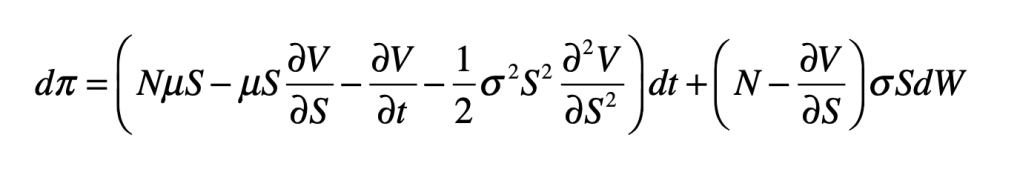
Note that the last term contains the fluctuations, expressed using the stochastic term dW (a random walk). The fluctuations can be zeroed-out by choosing
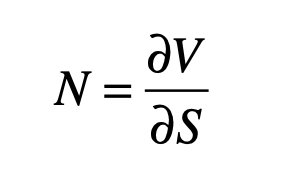
which yields
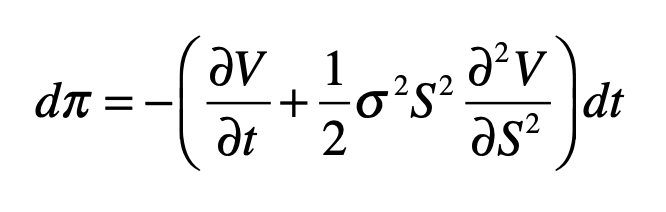
The important observation about this last equation is that the stochastic function W has disappeared. This is because the fluctuations of the N share prices balance the fluctuations of the short option.
When a broker buys an option, there is a guaranteed rate of return r at the time of maturity of the option which is set by the value of a risk-free bond. Therefore, the price of a perfect hedge must increase with the risk-free rate of return. This is
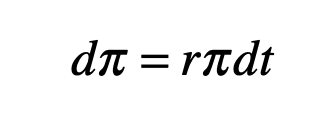
or
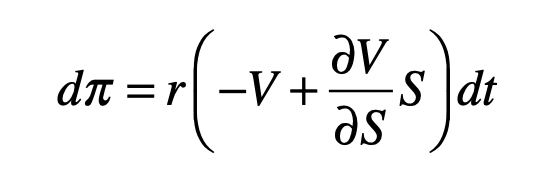
Equating the two equations gives
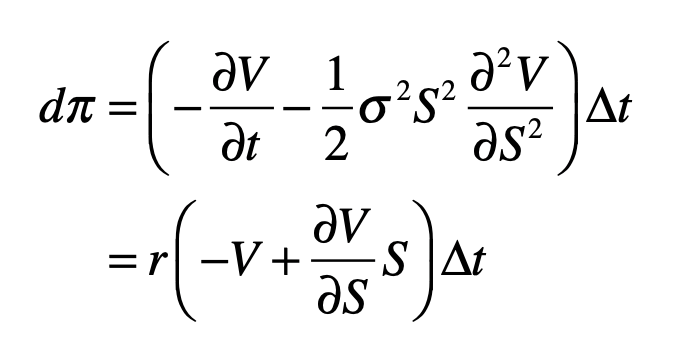
Simplifying, this leads to a partial differential equation for V(S,t)
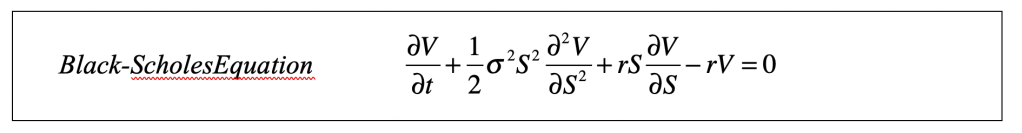
The Black-Scholes equation is a partial differential equation whose solution, given the boundary conditions and time, defines the “true” value of the derivative and determines how many shares to buy at t = 0 at a specified guaranteed return rate r (or, alternatively, stating a specified stock price S(T) at the time of maturity T of the option). It is a diffusion equation that incorporates the diffusion of the stock price with time. If the derivative is sold at any time t prior to maturity, when the stock has some value S, then the value of the derivative is given by V(S,t) as the solution to the Black-Scholes equation [1].
One of the interesting features of this equation is the absence of the mean rate of return μ of the underlying asset. This means that any stock of any value can be considered, even if the rate of return of the stock is negative! This type of derivative looks like a truly risk-free investment. You would be guaranteed to make money even if the value of the stock falls, which may sound too good to be true…which of course it is.

The success (or failure) of derivative markets depends on fundamental assumptions about the stock market. These include that it would not be subject to radical adjustments or to panic or irrational exuberance, i.i. Black-Swan events, which is clearly not the case. Just think of booms and busts. The efficient and rational market model, and ultimately the Black-Scholes equation, assumes that fluctuations in the market are governed by Gaussian random statistics. However, there are other types of statistics that are just as well behaved as the Gaussian, but which admit Black Swans.
Stable Distributions: Black Swans are the Norm
When Paul Lévy (1886 – 1971) was asked in 1919 to give three lectures on random variables at the École Polytechnique, the mathematical theory of probability was just a loose collection of principles and proofs. What emerged from those lectures was a lifetime of study in a field that now has grown to become one of the main branches of mathematics. He had a distinguished and productive career, although he struggled to navigate the anti-semitism of Vichy France during WWII. His thesis advisor was the famous Jacques Hadamard and one of his students was the famous Benoit Mandelbrot.
Lévy wrote several influential textbooks that established the foundations of probability theory, and his name has become nearly synonymous with the field. One of his books was on the theory of the addition of random variables [2] in which he extended the idea of a stable distribution.

In probability theory, a class of distributions are called stable if a sum of two independent random variables that come from a distribution have the same distribution. The normal (Gaussian) distribution clearly has this property because the sum of two normally distributed independent variables is also normally distributed. The variance and possibly the mean may be different, but the functional form is still Gaussian.

The general form of a probability distribution can be obtained by taking a Fourier transform as
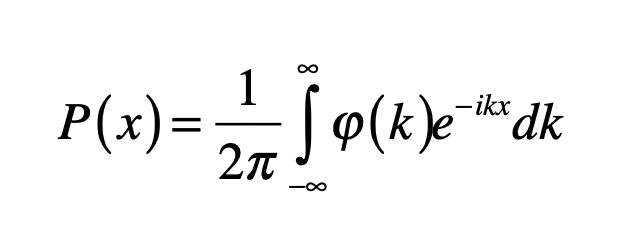
where φ is known as the characteristic function of the probability distribution. A special case of a stable distribution is the Lévy symmetric stable distribution obtained as
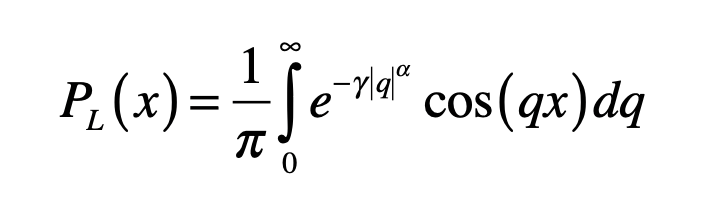
which is parameterized by α and γ. The characteristic function in this case is called a stretched exponential with the length scale set by the parameter γ.
The most important feature of the Lévy distribution is that it has a power-law tail at large values. For instance, the special case of the Lévy distribution for α = 1 is the Cauchy distribution for positive values x given by

which falls off at large values as x-(α+1). The Cauchy distribution is normalizable (probabilities integrate to unity) and has a characteristic scale set by γ, but it has a divergent mean value, violating the central limit theorem [3]. For distributions that satisfy the central limit theorem, increasing the number of samples from the distribution allows the mean value to converge on a finite value. However, for the Cauchy distribution increasing the number of samples increases the chances of obtaining a black swan, which skews the mean value, and the mean value diverges to infinity in the limit of an infinite number of samples. This is why the Cauchy distribution is said to have a “heavy tail” that contains rare, but large amplitude, outlier events that keep shifting the mean.
Examples of Levy stable probability distribution functions are shown below for a range between α = 1 (Cauchy) and α = 2 (Gaussian). The heavy tail is seen even for the case α = 1.99 very close to the Gaussian distribution. Examples of two-dimensional Levy walks are shown in the figure for α = 1, α = 1.4 and α = 2. In the case of the Gaussian distribution, the mean-squared displacement is well behaved and finite. However, for all the other cases, the mean-squared displacement is divergent, caused by the large path lengths that become more probable as α approaches unity.
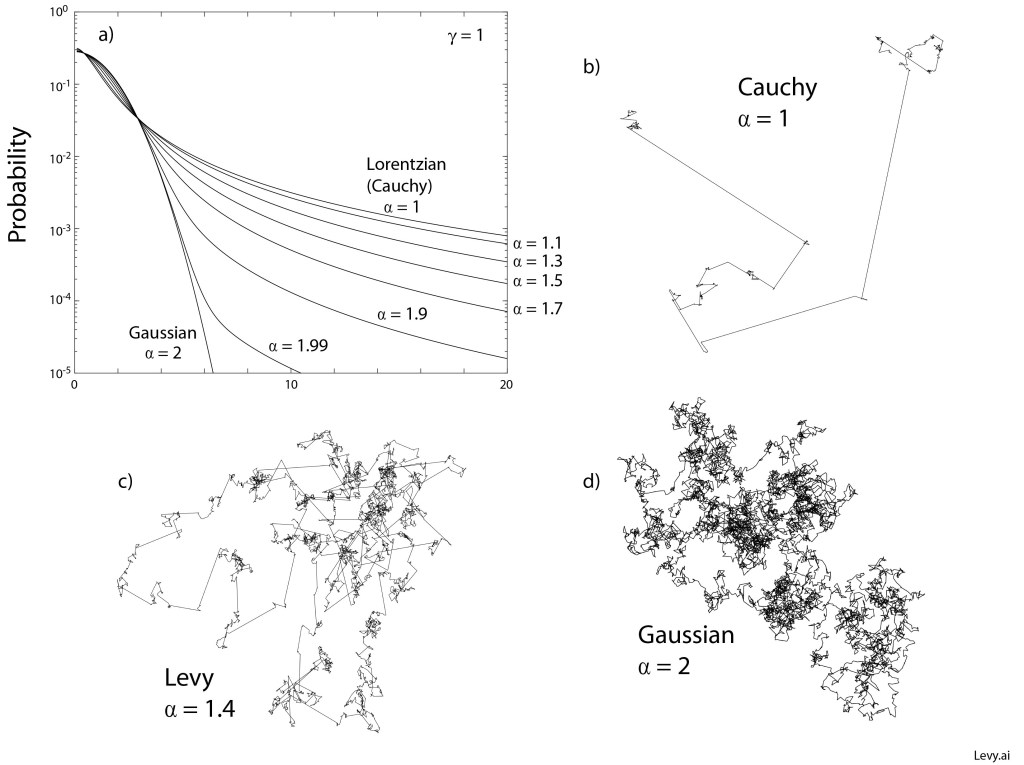
The surprising point of the Lévy probability distribution functions is how common they are in natural phenomena. Heavy Lévy tails arise commonly in almost any process that has scale invariance. Yet as students, we are virtually shielded from them, as if Poisson and Gaussian statistics are all we need to know, but ignorance is not bliss. The assumption of Gaussian statistics is what sank Black-Scholes.
Scale-invariant processes are often consequences of natural cascades of mass or energy and hence arise as neutral phenomena. Yet there are biased phenomena in which a Lévy process can lead to a form of optimization. This is the case for Lévy random walks in biological contexts.
Lévy Walks
The random walk is one of the cornerstones of statistical physics and forms the foundation for Brownian motion which has a long and rich history in physics. Einstein used Brownian motion to derive his famous statistical mechanics equation for diffusion, proving the existence of molecular matter. Jean Perrin won the Nobel prize for his experimental demonstrations of Einstein’s theory. Paul Langevin used Brownian motion to introduce stochastic differential equations into statistical physics. And Lévy used Brownian motion to illustrate applications of mathematical probability theory, writing his last influential book on the topic.
Most treatments of the random walk assume Gaussian or Poisson statistics for the step length or rate, but a special form of random walk emerges when the step length is drawn from a Lévy distribution. This is a Lévy random walk, also named a “Lévy Flight” by Benoit Mandelbrot (Lévy’s student) who studied its fractal character.
Originally, Lévy walks were studied as ideal mathematical models, but there have been a number of discoveries in recent years in which Lévy walks have been observed in the foraging behavior of animals, even in the run-and-tumble behavior of bacteria, in which rare long-distance runs are followed by many local tumbling excursions. It has been surmised that this foraging strategy allows an animal to optimally sample randomly-distributed food sources. There is evidence of Lévy walks of molecules in intracellular transport, which may arise from random motions within the crowded intracellular neighborhood. A middle ground has also been observed [4] in which intracellular organelles and vesicles may take on a Lévy walk character as they attach, migrate, and detach from molecular motors that drive them along the cytoskeleton.
By David D. Nolte, Feb. 8, 2023
Selected Bibliography
Paul Lévy, Calcul des probabilités (Gauthier-Villars, Paris, 1925).
Paul Lévy, Théorie de l’addition des variables aléatoires (Gauthier-Villars, Paris, 1937).
Paul Lévy, Processus stochastique et mouvement brownien (Gauthier-Villars, Paris, 1948).
R. Metzler, J. Klafter, The random walk’s guide to anomalous diffusion: a fractional dynamics approach. Physics Reports-Review Section Of Physics Letters 339, 1-77 (2000).
J. Klafter, I. M. Sokolov, First Steps in Random Walks : From Tools to Applications. (Oxford University Press, 2011).
F. Hoefling, T. Franosch, Anomalous transport in the crowded world of biological cells. Reports on Progress in Physics 76, (2013).
V. Zaburdaev, S. Denisov, J. Klafter, Levy walks. Reviews of Modern Physics 87, 483-530 (2015).
References
[1] Black, Fischer; Scholes, Myron (1973). “The Pricing of Options and Corporate Liabilities”. Journal of Political Economy. 81 (3): 637–654.
[2] P. Lévy, Théorie de l’addition des variables aléatoire (1937)
[3] The central limit theorem holds if the mean value of a number of N samples converges to a stable value as the number of samples increases to infinity.
[4] H. Choi, K. Jeong, J. Zuponcic, E. Ximenes, J. Turek, M. Ladisch, D. D. Nolte, Phase-Sensitive Intracellular Doppler Fluctuation Spectroscopy. Physical Review Applied 15, 024043 (2021).
This Blog Post is a Companion to the undergraduate physics textbook Modern Dynamics: Chaos, Networks, Space and Time, 2nd ed. (Oxford, 2019) introducing Lagrangians and Hamiltonians, chaos theory, complex systems, synchronization, neural networks, econophysics and Special and General Relativity.